链表
链表是线性数据结构。它是定义为节点的对象的集合。但是在链接列表中,节点存储在内存中的随机位置中,而不存储在连续位置中。

链表的一个节点包括:
-
数据项。
-
下一个节点的地址。
class Node {
int data;
Node *next;
};
节点的这种表示形式用于创建列表中的每个节点。数据字段存储元素,而*next 是存储下一个节点地址的指针。
第一个节点的地址称为头,最后一个节点的地址称为尾。链接列表中的最后一个节点指向 NULL。因此,当列表为空时,头节点指向 NULL 节点。链接列表不需要事先声明大小,并且可以动态增加大小。在链表中插入和删除元素非常容易。我们不需要移动所有要素;仅更改上一个和下一个元素的指针就足够了。
链接列表与数组的比较
链接列表比数组具有自然的优势,因为我们不必事先分配大量的内存,但是由于内存不是连续分配的,因此链接列表缓存起来也不友好。它们允许在指针的帮助下轻松地插入和删除元素,但由于指针所需的空间,每个节点的存储空间也要加倍。链接列表也不提供对元素的随机访问。因此,很明显,没有一个赢家,而且链表和数组都有各自的优缺点。
当我们有一个小列表并且知道我们可能存储的最大元素数量时,应该使用数组,而当有一个大列表定期更改时,应该使用链接列表。
链表遍历算法
令 head 成为链接列表的第一个节点。
-
初始化指向链接列表的
head节点的curr。 -
虽然
curr尚未到达列表的末尾,即curr!=NULL,但请执行以下操作:- 打印存储在当前节点内的数据。
curr=curr->next;
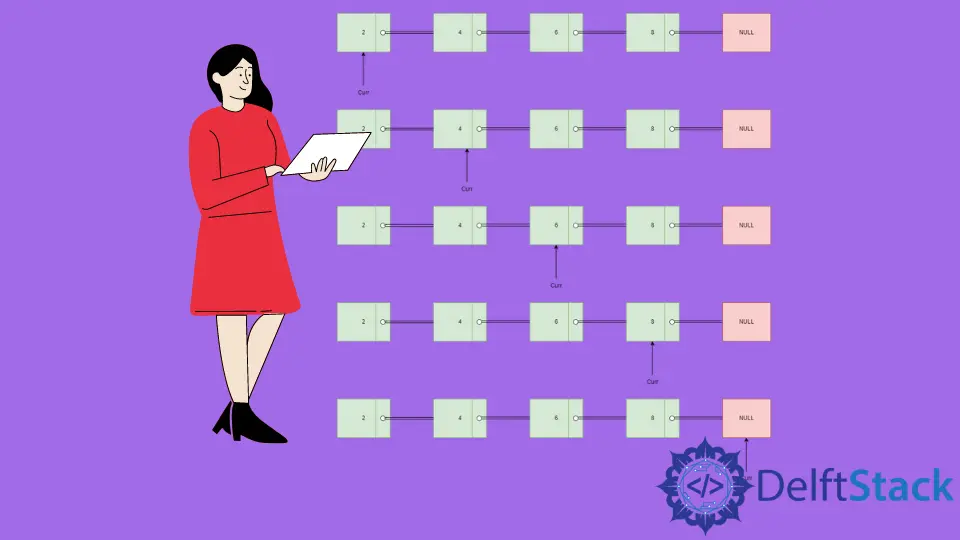
链表遍历图解

-
初始化指向
head节点的指针curr,数据值等于2。打印值2。 -
将指针
curr移动到下一个节点,数值为4。打印值4。 -
将指针
curr移动到下一个节点,数值为6。打印数值6。 -
将指针
curr移动到下一个节点,数值为8。打印值8。 -
将指针
curr移动到下一个节点,该节点的值等于NULL。达到while循环终止条件。因此,我们已经访问了所有的节点。
链表遍历实现
#include <bits/stdc++.h>
using namespace std;
class Node {
public:
int data;
Node* next;
Node(int x) {
this->data = x;
this->next = NULL;
}
};
void printList(Node* head) {
Node* curr = head;
while (curr != NULL) {
cout << curr->data << " ";
curr = curr->next;
}
}
int main() {
Node* head = new Node(1);
head->next = new Node(2);
head->next->next = new Node(3);
head->next->next->next = new Node(4);
head->next->next->next->next = new Node(5);
head->next->next->next->next->next = new Node(6);
printList(head);
return 0;
}
链表遍历算法复杂度
时间复杂度
- 平均情况
要遍历完整的链表,我们必须访问每个节点。因此,如果一个链表具有 n 个节点,则遍历的平均情况下时间复杂度约为 O(n)。时间复杂度约为 O(n)。
- 最佳情况
最佳情况下的时间复杂度是 O(n)。它与平均情况下的时间复杂度相同。
- 最坏情况
最坏情况下的时间复杂度是 O(n)。它与最佳情况下的时间复杂度相同。
空间复杂度
该遍历算法的空间复杂度为 O(1),因为除 curr 指针外不需要其他空间。

Harshit Jindal has done his Bachelors in Computer Science Engineering(2021) from DTU. He has always been a problem solver and now turned that into his profession. Currently working at M365 Cloud Security team(Torus) on Cloud Security Services and Datacenter Buildout Automation.
LinkedIn