OpenCV 对象检测

本教程将讨论使用 OpenCV 中的级联分类器和 YOLO 检测图像或视频流中的对象。
在 OpenCV 中使用级联分类器进行对象检测
我们可以检测图像中存在的对象,例如人脸、动物脸、眼睛等。我们可以使用 OpenCV 的 CascadeClassifier 类来检测图像中存在的对象。
级联分类器使用 Haar 特征来使用级联特征检测对象。我们必须使用经过训练的模型,其中包含我们想要在图像中检测到的对象的特征。
OpenCV 有许多基于 Haar 特征的预训练模型。该算法从输入图像中生成窗口,然后将它们与特征集进行比较。
单个预训练模型包含大约 160,000 个特征,将窗口与每个特征进行比较需要大量时间。
所以算法从特征中进行级联,如果一个窗口与第一个级联匹配,它将与第二个级联进行比较;否则,它将被丢弃。
这样,算法将花费更少的时间来检测物体。例如,让我们使用包含猫和人的图像和级联分类器来检测图像中存在的眼睛。
请参阅下面的代码。
import cv2
src_img = cv2.imread("animal.jpg")
gray_img = cv2.cvtColor(src_img, cv2.COLOR_BGR2GRAY)
c_classifier = cv2.CascadeClassifier(f"{cv2.data.haarcascades}haarcascade_eye.xml")
d_objects = c_classifier.detectMultiScale(gray_img, minSize=(50, 50))
if len(d_objects) != 0:
for (x, y, h, w) in d_objects:
cv2.rectangle(src_img, (x, y), ((x + h), (y + w)), (0, 255, 255), 5)
cv2.imshow("Detected Objects", src_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出:

在上面的代码中,我们使用预训练模型 haarcascade_eye.xml 进行眼睛检测,但我们可以使用许多其他预训练模型,例如面部、微笑和身体检测。预训练模型保存在 OpenCV 的数据文件夹中,也可以在此链接中找到它们。
我们使用级联分类器的 detectMultiScale() 函数来检测对象。该函数将为每个对象返回一个向量,其中包含 x 和 y 坐标以及检测到的对象的宽度和高度。
我们可以使用此输出在检测到的对象周围绘制一个形状,例如矩形或圆形。
detectMultiScale() 函数的第一个参数是灰度输入图像。第二个参数 minSize 用于设置我们想要检测的对象的最小尺寸。
我们还可以在 detectMultiScale() 函数中设置其他可选参数。第一个可选参数是 scaleFactor,用于设置图像比例,默认设置为 1.1。
第二个可选参数是 minNeighbors,它用于设置用于对象检测的最小邻居数,默认情况下,其值设置为 3。第三个可选参数是 maxSize,它设置我们想要检测的对象的最大尺寸。
我们使用 OpenCV 的 rectangle() 函数在检测到的对象周围绘制一个矩形。第一个参数是我们要在其上绘制矩形的图像。
第二个和第三个参数是矩形的开始和结束位置。第四个参数用于定义 BGR 色标中的颜色,第五个参数用于设置矩形的线宽。
预训练的模型大多包含面部特征,但我们也可以制作我们的模型用于对象检测。查看此链接了解有关级联分类器模型训练的更多详细信息。
在 OpenCV 中使用 YOLO 进行目标检测
多个检测器被用于对象检测,如单次检测器、RNN 和快速 RNN。与其他检测器相比,单次检测器速度快,但精度较低。
YOLO 就像一个单次检测器,与单次检测器相比速度快但与单次检测器具有相同的精度。YOLO 将整个图像通过深度神经网络来检测图像或视频中存在的对象。
该算法找到图像中存在的对象周围的边界框及其置信度,并根据置信度过滤框。如果某个框的置信度低于特定值,则该框将被丢弃。
YOLO 还使用非最大抑制技术来消除单个对象周围的重叠边界框。这样,我们只会得到一个围绕一个对象的边界框。
YOLO 为深度神经网络预训练了权重和配置,我们可以使用 OpenCV 的 dnn.readNetFromDarknet() 函数加载它们。我们还可以获取 COCO 数据集中存在的不同对象的类名。
我们必须下载 weights、configurations 和 COCO 名称文件才能在 OpenCV 中使用它们。我们可以使用 COCO 名称将对象的名称放在边界框上。
加载数据后,我们必须读取图像并使用 dnn.blobFromImage() 函数创建一个 blob,然后我们可以使用 setInput() 函数将其传递到深度神经网络。
我们可以使用 setPreferableBackend() 函数将神经网络的首选后端设置为 OpenCV。我们还可以使用 setPreferableTarget() 函数将首选目标设置为 CPU 或 GPU。
如果我们有 GPU,YOLO 会比 CPU 运行得更快。我们必须运行网络直到最后一层,我们可以使用 getLayerNames() 函数来查找层名称和 getUnconnectedOutLayers() 函数来获取最后一层。
现在我们将使用一个循环来查找边界框及其置信度,如果置信度低于特定值,则丢弃该框,并保存其他框。
之后,我们将使用 dnn.NMSBoxes() 函数使用非最大抑制技术过滤框。
dnn.NMSBoxes() 函数将返回我们的 x 和 y 坐标以及边界框的宽度和高度,我们可以将这些值传递给 rectangle() 函数以在每个检测到的对象周围绘制一个矩形。
我们可以使用 OpenCV 的 putText() 函数将对象名称放在使用 COCO 名称的矩形顶部。
例如,让我们使用图像并使用 YOLO 查找存在的对象。请参阅下面的代码。
import cv2
import numpy as np
img_src = cv2.imread("animal.jpg")
cv2.imshow("window", img_src)
cv2.waitKey(1)
classes_names = open("coco.names").read().strip().split("\n")
np.random.seed(42)
colors_rnd = np.random.randint(0, 255, size=(len(classes_names), 3), dtype="uint8")
net_yolo = cv2.dnn.readNetFromDarknet("yolov3.cfg", "yolov3.weights")
net_yolo.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
net_yolo.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
ln = net_yolo.getLayerNames()
ln = [ln[i - 1] for i in net_yolo.getUnconnectedOutLayers()]
blob_img = cv2.dnn.blobFromImage(
img_src, 1 / 255.0, (416, 416), swapRB=True, crop=False
)
r_blob = blob_img[0, 0, :, :]
cv2.imshow("blob", r_blob)
text = f"Blob shape={blob_img.shape}"
net_yolo.setInput(blob_img)
outputs = net_yolo.forward(ln)
boxes = []
confidences = []
classIDs = []
h, w = img_src.shape[:2]
for output in outputs:
for detection in output:
scores_yolo = detection[5:]
classID = np.argmax(scores_yolo)
confidence = scores_yolo[classID]
if confidence > 0.5:
box_rect = detection[:4] * np.array([w, h, w, h])
(centerX, centerY, width, height) = box_rect.astype("int")
x_c = int(centerX - (width / 2))
y_c = int(centerY - (height / 2))
box_rect = [x_c, y_c, int(width), int(height)]
boxes.append(box_rect)
confidences.append(float(confidence))
classIDs.append(classID)
indices_yolo = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
if len(indices_yolo) > 0:
for i in indices_yolo.flatten():
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
color = [int(c) for c in colors_rnd[classIDs[i]]]
cv2.rectangle(img_src, (x, y), (x + w, y + h), color, 3)
text = "{}: {:.4f}".format(classes_names[classIDs[i]], confidences[i])
cv2.putText(img_src, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.6, color, 2)
cv2.imshow("window", img_src)
cv2.waitKey(0)
cv2.destroyAllWindows()
输出:
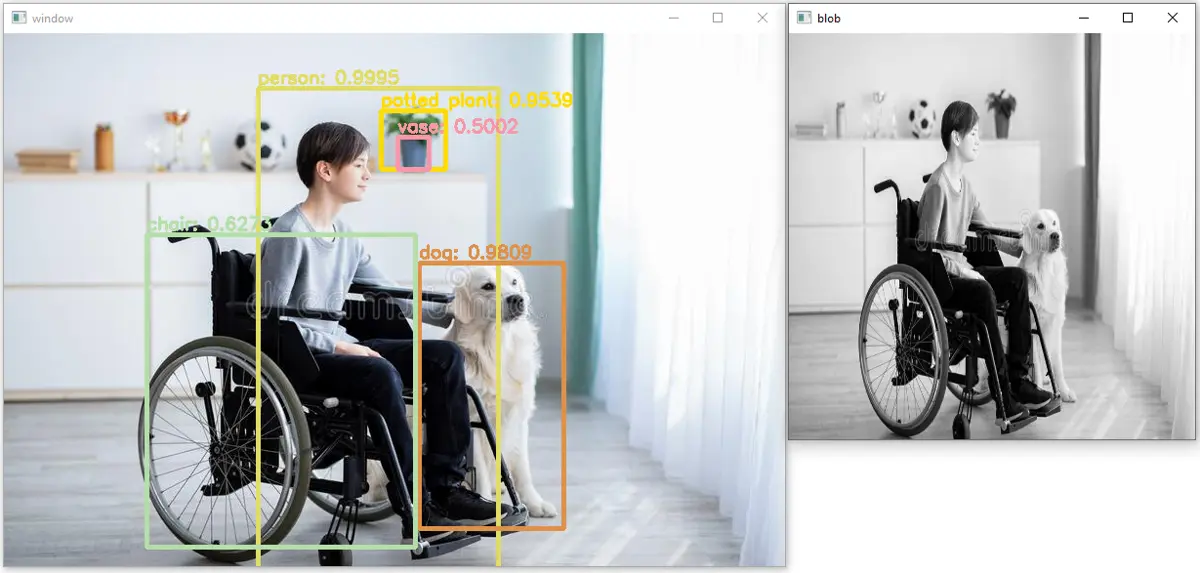
如我们所见,在上图中已经检测到五个对象,它们的准确度或置信度也被置于矩形之上。我们也可以将相同的代码应用于视频;我们必须读取每一帧,在每一帧上应用上面的代码,然后再次将帧保存在视频中。
在上面的代码中,np.random.randint() 函数用于创建随机颜色。第一个参数是颜色的起始值,第二个参数是颜色的结束值。
第三个参数 size 用于设置每种颜色的大小,第四个参数 dtype 用于设置输出的数据类型。append() 函数将值添加到给定的数组中。
OpenCV 的 rectangle() 函数用于在检测到的对象周围绘制矩形。第一个参数是我们要在其上绘制矩形的图像。
第二个参数是矩形左上角的起点或位置,第三个参数是矩形的终点或右上角的位置。第四个参数是颜色,第五个参数是矩形的线宽。
putText() 函数用于在图像上放置文本。第一个参数是我们要在其上放置文本的图像,第二个参数是我们要在图像上放置的文本。
第三个参数是文本的起始位置,第四个参数是文本的字体样式。第五个参数用于设置字体比例,第六个参数用于设置文本的线宽。
