在 Python Pandas 中使用 str.split 将字符串拆分为两个列表列
-
在 Python Pandas 中使用
str.split()函数将字符串拆分为两个列表/列 - 使用基本语法将 Pandas DataFrame 中的字符串列拆分为多列
- 在 Python Pandas 中将字符串转换为列表
- 在 Python Pandas 中从字符串创建单独的列
- 结论

Pandas 有一种基于分隔符/定界符拆分字符串的方法。我们将使用 pandas str.split() 函数。
在 Python Pandas 中使用 str.split() 函数将字符串拆分为两个列表/列
该字符串可以保存为系列列表,也可以由单个分隔的字符串、多列 DataFrame 构成。
使用的函数类似于 Python 的默认 split() 方法,但它们只能应用于单个字符串。
语法:
Syntax:Series.str.split(pat=None, n=-1, expand=False)
Let's define each of the parameters of syntax
Parameters:
pat:String value, separator, or delimiter used to separate strings
n=The maximum number of separations to make in a single string; the default is -1, which signifies all.
expand: If True, this Boolean value returns a data frame with different values in separate columns. Otherwise, it returns a series containing a collection of strings.
return: Depending on the expand parameter, a series of lists or a data frame will be generated.
首先,我们用一个简单的例子来解释,然后是一个 CSV 文件。
使用基本语法将 Pandas DataFrame 中的字符串列拆分为多列
data[["A", "B"]] = data["A"].str.split(",", 1, expand=True)
请参阅下面的示例,这些示例演示了此语法在实践中的使用。
按逗号拆分列:
import pandas as pd
df = pd.DataFrame(
{"Name": ["Anu,Ais ", "Bag, Box", "fox, fix"], "points": [112, 104, 127]}
)
df
输出:

# split team column into two columns
df[["Name", "lastname"]] = df["Name"].str.split(",", 2, expand=True)
df
输出:

对于代码中使用的 CSV 文件下载,请单击此处。
学生成绩数据包含在以下示例中使用的 DataFrame 中。附加任何操作之前的 DataFrame 图像。
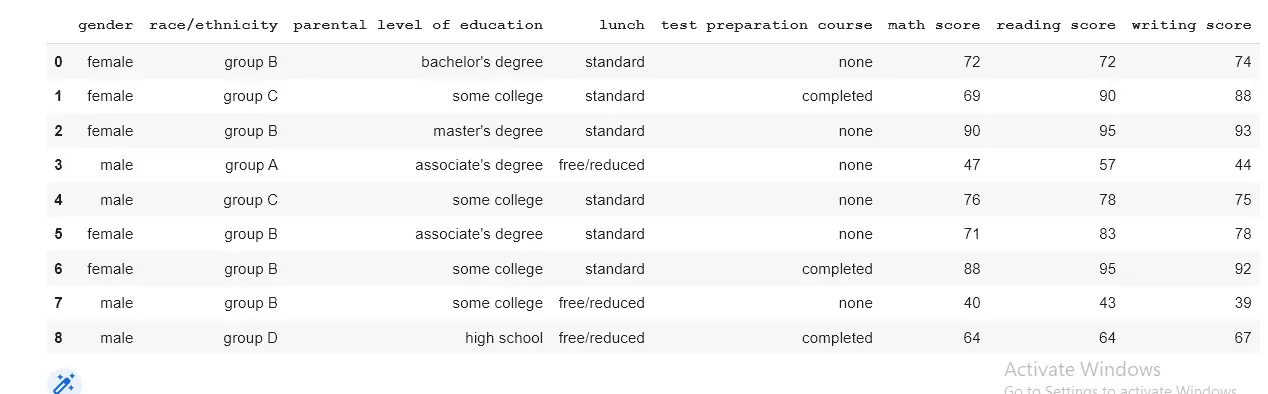
我们以两种方式解释字符串的拆分。
- 将字符串转换为列表
- 从字符串创建单独的列
在 Python Pandas 中将字符串转换为列表
在此数据中使用 split 函数在每个 d 处拆分午餐列。该选项设置为 1,单个字符串中的最大分隔数为 1。
expand 参数设置为 False。返回的不是一系列 DataFrame,而是一个字符串列表。
import pandas as pd
df = pd.read_csv("/content/drive/MyDrive/StudentsPerformance.csv")
# dropping null value columns to avoid errors
df.dropna(inplace=True)
# new data frame with split value columns
df["lunch"] = df["lunch"].str.split("d", n=1, expand=True)
# df display
df.head(9)
输出:
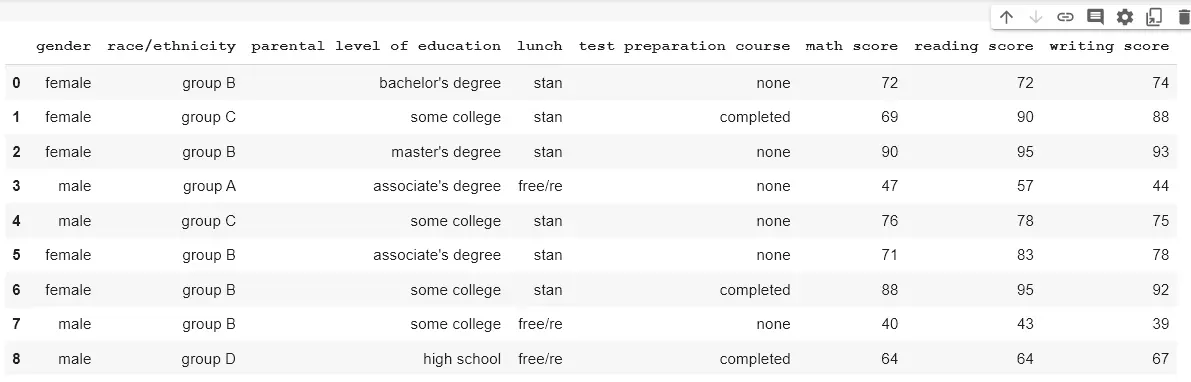
输出图像显示午餐列现在有一个列表,因为 n 选项设置为 1。
字符串在第一次出现 d 时被分隔,而不是在后续出现时分隔(字符串中最多 1 次分隔)。
在 Python Pandas 中从字符串创建单独的列
在此示例中,父母教育程度列由空格" " 分隔,并且扩展选项设置为 True。
这意味着它将返回一个 DataFrame,其中所有分隔的字符串位于不同的列中。然后使用 Dataframe 构建新列。
使用 drop() 方法删除旧的父母教育水平列。
import pandas as pd
df = pd.read_csv("/content/drive/MyDrive/StudentsPerformance.csv")
# dropping null value columns to avoid errors
df.dropna(inplace=True)
new = df["parental level of education"].str.split(" ", n=1, expand=True)
df["educational level"] = new[0]
df["insititute"] = new[1]
# Dropping old Name columns
df.drop(columns=["parental level of education"], inplace=True)
# df display
df.head(9)
输出:
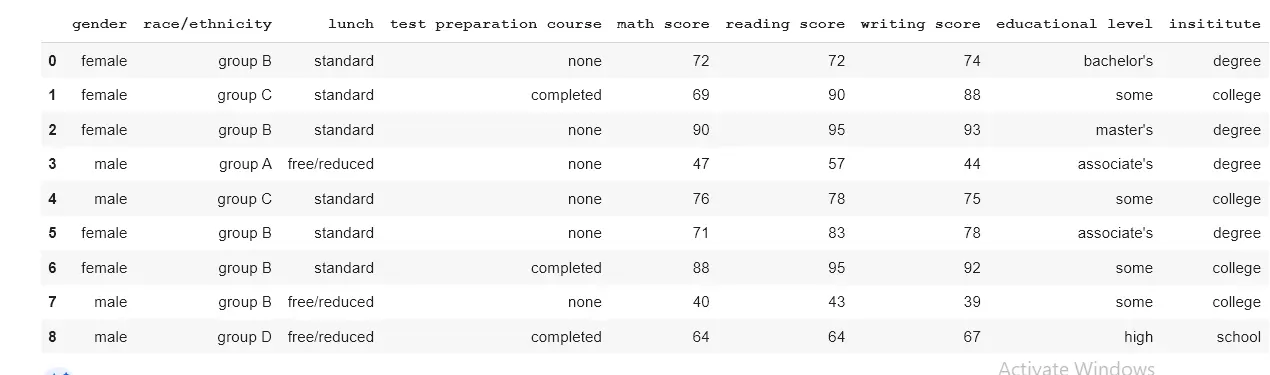
split() 函数提供了一个新的 DataFrame,该 DataFrame 在 DataFrame 中创建了两个新列(教育级别和学院)。
上图显示了新列。我们还可以使用显示新创建的列的新关键字查看新列。
new.head(9)
输出:

结论
因此,在你的 Pandas 信息框中通常有一个部分需要在信息大纲中分成两个部分。
例如,如果你的信息大纲中的某个部分是全名,你可能需要将其分为名字和姓氏。