在 Pandas 中执行 SQL 查询

SQL 代表结构化查询语言;它是一种用于与关系数据库交互的著名语言。在 Python 中运行 SQL 查询有很多方法。
在 Python 中使用 pandasql 运行 SQL 查询
这个包有一个类似 R 中的 sqldf 的 sqldf 方法。pandasql 提供了一种更熟悉的方式来对 DataFrame 执行 CRUD 操作。
在我们使用 pandasql 之前,我们必须先使用以下命令安装它。
#Python 3.x
pip install -U pandasql
我们将从 pandasql 模块导入 sqldf 方法来运行查询。然后我们将调用带有两个参数的 sqldf 方法。
第一个参数是字符串格式的 SQL 查询。第二个参数是一组会话/环境变量(globals() 或 locals())。
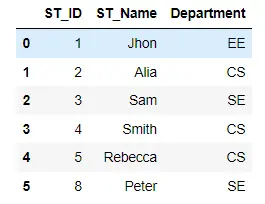
在以下代码中,首先,我们将 Student.csv 数据上传到 Jupyter 笔记本的当前工作目录。然后我们在 DataFrame 上使用传统的 SQL Select 查询读取了学生的记录;它将显示 DataFrame 中的所有记录。
# Python 3.x
import pandas as pd
from pandasql import sqldf
def mysql(q):
return sqldf(q, globals())
df = pd.read_csv("Student.csv")
mysql("SELECT * FROM df")
输出:
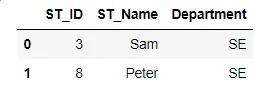
我们在 SQL 查询中使用了 WHERE 子句,仅显示满足以下代码中给定条件的选定记录。
# Python 3.x
import pandas as pd
from pandasql import sqldf
def mysql(q):
return sqldf(q, globals())
df = pd.read_csv("Student.csv")
mysql("SELECT * FROM df WHERE Department = 'SE'")
输出:
在 Python 中使用 DuckDB 运行 SQL 查询
DuckDB 是一个 Python API 和一个使用 SQL 查询与数据库交互的数据库管理系统。
要使用 DuckDB,我们应该首先使用以下命令安装它。
#Python 3.x
pip install duckdb
在下面的代码中,我们导入了 duckdb 和 Pandas 包,读取 CSV 文件并通过使用 duckdb 调用 query() 方法来运行查询。我们将查询(作为参数)传递给 query() 方法。
代码将结果作为 DataFrame 返回。我们可以根据 DataFrame 编写我们选择的任何 SQL 查询。
# Python 3.x
import pandas as pd
import duckdb
df = pd.read_csv("Student.csv")
duckdb.query("SELECT * FROM df").df()
输出:
在 Python 中使用 Fugue 运行 SQL 查询
Fugue 是分布式计算的统一接口,允许用户在 Spark 和 Dask 上运行 Python、Pandas 和 SQL 代码而无需重写。
我们必须先使用以下命令安装它才能使用 fugue。
#Python 3.x
pip install fugue[sql]
我们在以下代码中导入了 Pandas 和 fugue 包,并使用 CSV 文件加载了 DataFrame。然后我们将我们的 SQL 查询传递给 fsql() 方法并使用它调用 run() 方法。
# Python 3.x
import pandas as pd
from fugue_sql import fsql
df = pd.read_csv("Student.csv")
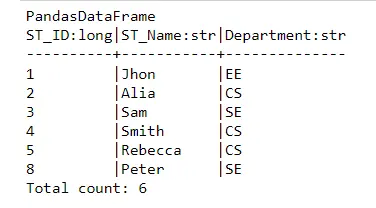
query = "SELECT * FROM df PRINT"
fsql(query).run()
输出:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn