绘制 Pandas 中的 Series
- Pandas 中的各种图
- 从 Pandas 系列中绘制条形图
- 绘制 Pandas 系列的线图
- 绘制 Pandas 系列的箱线图
- 绘制 Pandas 系列的直方图 Bin 图
- 绘制 Pandas 系列的自相关图
本文探讨了使用 Pandas 在 DataFrame 上绘制系列的概念。
无论你是在探索数据集以磨练自己的技能,还是旨在为公司绩效分析做出良好的演示,可视化都起着重要作用。
Python 通过其带有 .plot() 函数的 Pandas 库提供了各种选项,以前所未有的形式将我们的数据转换为可呈现的形式。
即使是业余 Python 开发人员在了解了步骤并遵循正确的程序以产生有价值的见解后,也很容易知道如何使用该库。
但是,要做到这一点,我们首先需要了解库的功能以及它如何帮助分析师为公司提供价值。
Pandas 中的各种图
让我们通过了解当前存在多少不同的图来开始本教程。
line- 线图(这是默认图)bar- 平行于 Y 轴(垂直)的条形图barh- 平行于 X 轴的条形图(水平)hist- 直方图box- 箱线图kde- 核密度估计图density- 与kde相同area- 面积图pie- 饼图
Pandas 使用 plot() 方法进行可视化。此外,pyplot 可以使用 Matplotlib 库用于图示。
本教程涵盖了重要的绘图类型以及如何有效地使用它们。
从 Pandas 系列中绘制条形图
顾名思义,当数据为系列形式时,系列图很重要,并且变量之间应该存在相关性。如果没有相关性,我们就不会进行可视化和比较。
下面是一个基于以字典形式给出的虚拟数据绘制基本条形图的示例。我们可以使用基于真实数据的 CSV 文件,也可以使用自定义创建的虚拟数据来探索开发和研究的各种选项。
import pandas as pd
import matplotlib.pyplot as plt
s = pd.Series(
{
16976: 2,
1: 39,
2: 49,
3: 187,
4: 159,
5: 158,
16947: 14,
16977: 1,
16948: 7,
16978: 1,
16980: 1,
},
name="article_id",
)
print(s)
# Name: article_id, dtype: int64
s.plot.bar()
plt.show()
上面的代码给出了这个输出。
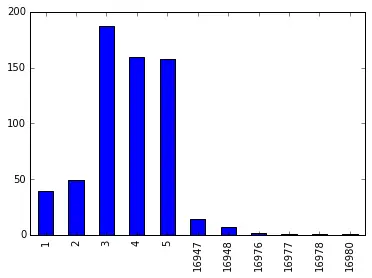
正如我们所看到的,显示了一个条形图以帮助进行比较和分析。
绘制 Pandas 系列的线图
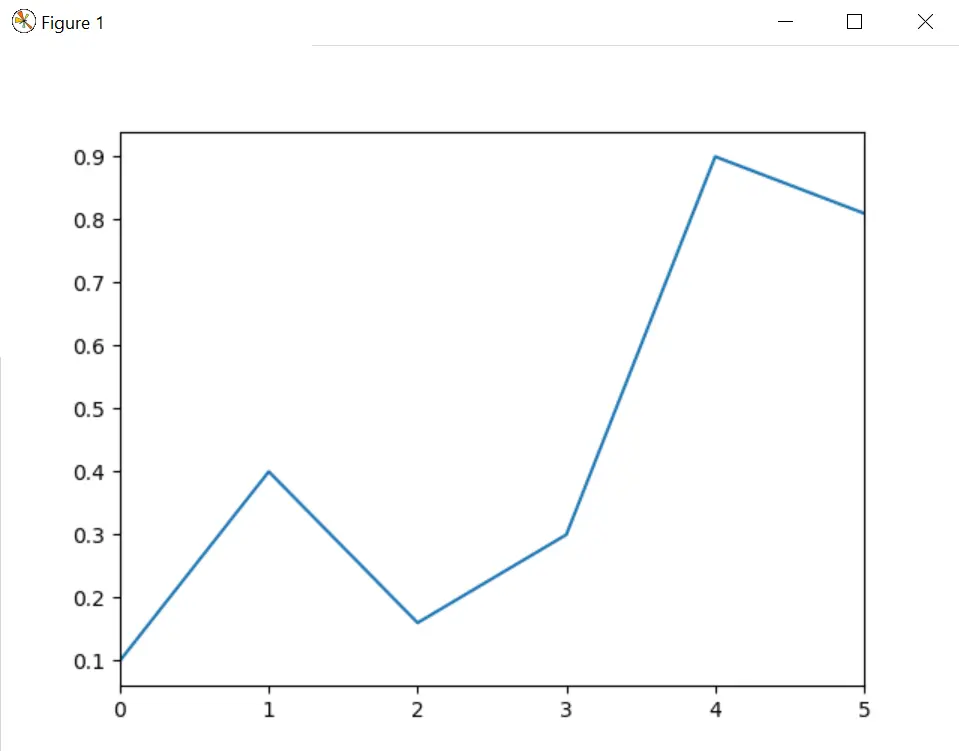
让我们再考虑一个例子,我们的目的是根据给定的虚拟数据绘制折线图。在这里,我们不应该添加额外的元素和 plot()。
# using Series.plot() method
s = pd.Series([0.1, 0.4, 0.16, 0.3, 0.9, 0.81])
s.plot()
plt.show()
上面的代码给出了这个输出。
也可以绘制在 Y 轴上包含多个变量的图表,如下所示。在单个图中包含多个变量使得比较属于同一类别的元素更具说明性和可行性。
例如,如果创建了学生在特定考试中的分数图,它将帮助教授分析每个学生在特定时间间隔内的表现。
import numpy as np
ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))
df = df.cumsum()
plt.figure()
df.plot()
plt.show()
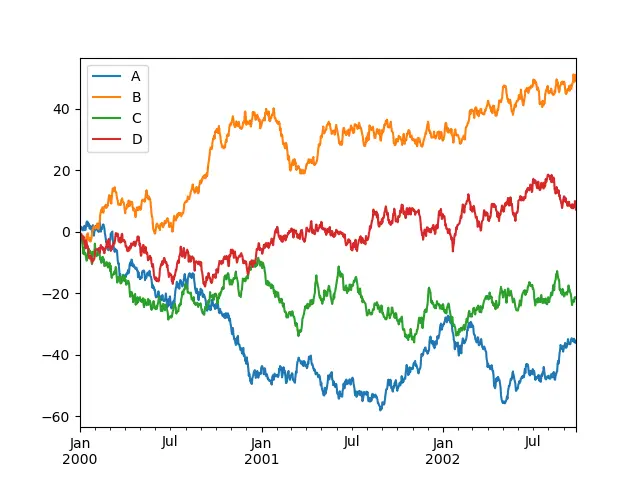
绘制 Pandas 系列的箱线图
plot() 方法允许除默认线图以外的其他绘图样式。我们可以提供 kind 参数和 plot 函数。
我们可以通过调用函数 series.plot.box() 绘制箱线图来说明每列内的值分布。箱线图告诉我们很多关于数据的信息,例如中位数。
我们还可以通过查看箱线图找出第一个、第二个和第三个四分位数。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"])
df.plot.box()
plt.show()
此外,使用 color 关键字传递其他类型的参数将立即分配给 matplotlib,用于所有 boxes、whiskers、medians 和 caps 着色。
我们只需写一行就可以获取下面给出的这个信息图表。
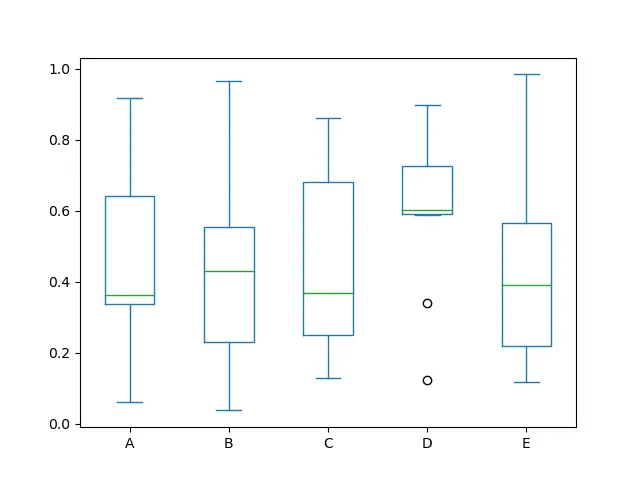
return_type 关键字来控制返回类型。绘制 Pandas 系列的直方图 Bin 图
接下来,我们将学习如何绘制六边形 bin 图和自相关图。
直方图 Bin 图是使用 dataframe.plot.hexbin() 语法创建的。如果数据太密集而无法清楚地绘制每个点,这些是散点图的良好替代品。
在这里,一个非常重要的关键字是 gridsize,因为它控制沿水平方向的六边形的数量。更多的网格将倾向于更小和更大的箱。
以下是基于随机数据的以下代码片段。
df = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
df["b"] = df["b"] + np.arange(1000)
df["z"] = np.random.uniform(0, 3, 1000)
df.plot.hexbin(x="a", y="b", C="z", reduce_C_function=np.max, gridsize=25)
plt.show()
上面的代码给出了这个输出。
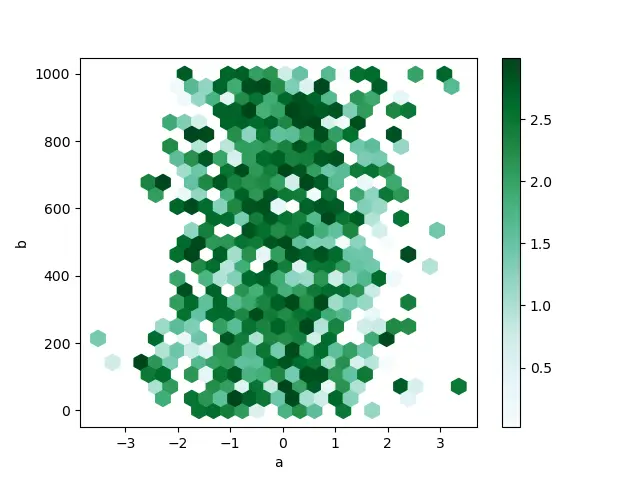
有关六边形 bin 图的更多信息,请导航到 Pandas 官方文档中的 hexbin 方法。
绘制 Pandas 系列的自相关图
我们以最复杂的绘图类型结束本教程:自相关图。该图通常用于分析基于神经网络的机器学习模型。
它用于描述时间序列中的元素是否正相关、负相关或不相互依赖。我们可以在 Y 轴上找出 自相关 函数 ACF 的值,范围从 -1 到 1
它有助于纠正时间序列中的随机性。我们通过计算不同时间滞后的自相关来获得数据。
平行于 X 轴的线对应于大约 95% 到 99% 的置信带。虚线是 99% 置信带。
让我们看看如何创建这个图。
from pandas.plotting import autocorrelation_plot
plt.figure()
spacing = np.linspace(-9 * np.pi, 9 * np.pi, num=1000)
data = pd.Series(0.7 * np.random.rand(1000) + 0.3 * np.sin(spacing))
autocorrelation_plot(data)
plt.show()
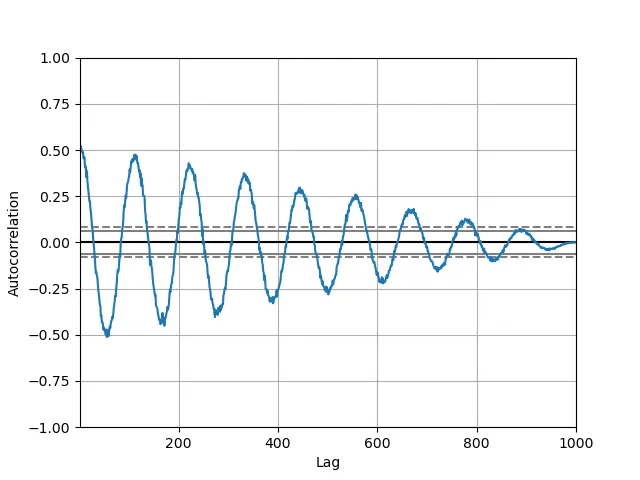
如果时间序列不是基于真实数据,那么这种自相关对于所有时滞差异都在零附近,如果时间序列基于真实数据,那么自相关必须是非零的。必须有一个或多个自相关。
