在 Pandas DataFrame 中规范化一列
- Pandas 中的数据归一化
-
用
mean归一化来归纳 Pandas DataFrame -
用
最小-最大归一化方法对 Pandas DataFrame 进行归一化 -
使用
分位数归一化对 Pandas DataFrame 进行归一化

数据的标准化或归一化是特征工程的第一步。列的归一化将涉及到把列的值带到一个共同的尺度,主要是针对范围不同的列进行的。在 Pandas 中,可以通过各种函数对 Dataframes 的列进行归一化。本文将帮助你练习这些函数,并帮助你在正确的情况下应用这些函数。
Pandas 中的数据归一化
有两种最广泛使用的数据归一化方法。
- 平均值归一化
- 最小-最大归一化
- 量子化标准化
在 Pandas 中并没有任何特定的方法来执行数据归一化。我们将解释这些归一化是什么,以及如何使用原生 Pandas 和一点原生 python 函数来实现它。
我们将在各个地方使用下面的代码段来创建一个带有随机元素的 DataFrame,如下图所示,它将返回一个类似的 DataFrame。
import pandas as pd
import numpy as np
np.random.seed(0)
df = pd.DataFrame(np.random.randint(-100, 100, size=(20, 4)), columns=list("ABCD"))
print(df)
它将返回一个类似的 DataFrame,如下所示。
A B C D
0 72 -53 17 92
1 -33 95 3 -91
2 -79 -64 -13 -30
3 -12 40 -42 93
4 -61 -13 74 -12
5 -19 65 -75 -23
6 -28 -91 48 15
7 97 -21 75 92
8 -18 -1 77 -71
9 47 47 42 67
10 -68 93 -91 85
11 27 -68 -69 51
12 63 14 83 -72
13 -66 28 28 64
14 -47 33 -62 -83
15 -21 32 5 -58
16 86 -69 20 -99
17 -35 69 -43 -65
18 2 19 -89 74
19 -18 -9 28 42
[20 rows x 4 columns]
用 mean 归一化来归纳 Pandas DataFrame
“均值 “归一化是对不同范围的 DataFrame 进行归一化的最简单方法之一。归一化是通过减去 DataFrame 所有元素的平均值并除以标准差来完成的。
import pandas as pd
import numpy as np
np.random.seed(0)
df = pd.DataFrame(np.random.randint(-100, 100, size=(20, 4)), columns=list("ABCD"))
def mean_norm(df_input):
return df_input.apply(lambda x: (x - x.mean()) / x.std(), axis=0)
df_mean_norm = mean_norm(df)
print(df_mean_norm)
输出:
A B C D
0 1.452954 -1.090261 0.278088 1.247208
1 -0.514295 1.585670 0.037765 -1.333223
2 -1.376137 -1.289148 -0.236890 -0.473079
3 -0.120845 0.591236 -0.734701 1.261309
4 -1.038895 -0.367037 1.256545 -0.219266
5 -0.251995 1.043252 -1.301176 -0.374374
6 -0.420617 -1.777325 0.810231 0.161453
7 1.921346 -0.511681 1.273711 1.247208
8 -0.233260 -0.150069 1.308043 -1.051208
9 0.984561 0.717801 0.707236 0.894690
10 -1.170045 1.549509 -1.575831 1.148503
11 0.609847 -1.361470 -1.198181 0.669079
12 1.284333 0.121140 1.411038 -1.065309
13 -1.132573 0.374269 0.466913 0.852388
14 -0.776595 0.464672 -1.078020 -1.220417
15 -0.289467 0.446591 0.072097 -0.867899
16 1.715254 -1.379551 0.329586 -1.446028
17 -0.551766 1.115574 -0.751867 -0.966604
18 0.141455 0.211543 -1.541499 0.993395
19 -0.233260 -0.294714 0.466913 0.542172
如果你使用的是 Jupyter 笔记本,可以使用 Matplotlib 对两个 DataFrame 进行可视化,如下图所示。
# %matplotlib inline
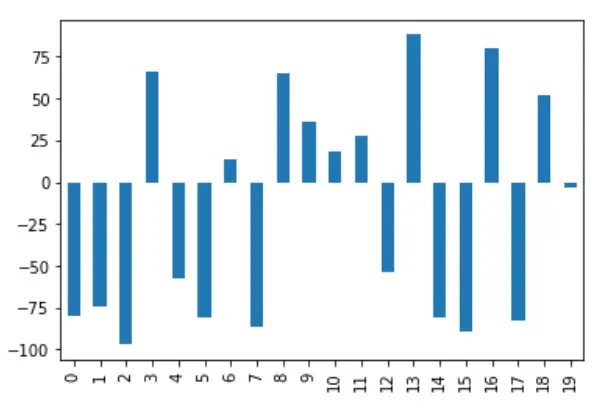
df["A"].plot(kind="bar")
通过选择归一化前的 DataFrame 的 A 列,并将其可视化为一个条形图,注意到 y 轴包含-100 到 100 的范围内的值。
# %matplotlib inline
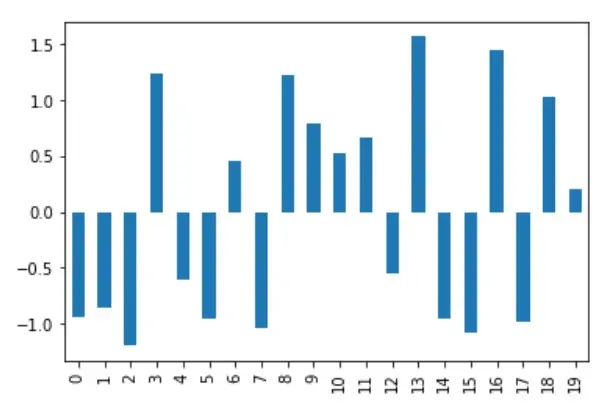
df_mean_norm["A"].plot(kind="bar")
下图显示了归一化后的数据;当同一列可视化时,y 轴位于-1.5 至+1.5 的范围内。
用 最小-最大 归一化方法对 Pandas DataFrame 进行归一化
这是广泛使用的归一化方法之一。归一化输出减去 DataFrame 的最小值,然后除以相应列的最高值和最低值之差。
import pandas as pd
import numpy as np
np.random.seed(0)
df = pd.DataFrame(np.random.randint(-100, 100, size=(20, 4)), columns=list("ABCD"))
def minmax_norm(df_input):
return (df - df.min()) / (df.max() - df.min())
df_minmax_norm = minmax_norm(df)
print(df_minmax_norm)
输出:
A B C D
0 0.857955 0.204301 0.620690 0.994792
1 0.261364 1.000000 0.540230 0.041667
2 0.000000 0.145161 0.448276 0.359375
3 0.380682 0.704301 0.281609 1.000000
4 0.102273 0.419355 0.948276 0.453125
5 0.340909 0.838710 0.091954 0.395833
6 0.289773 0.000000 0.798851 0.593750
7 1.000000 0.376344 0.954023 0.994792
8 0.346591 0.483871 0.965517 0.145833
9 0.715909 0.741935 0.764368 0.864583
10 0.062500 0.989247 0.000000 0.958333
11 0.602273 0.123656 0.126437 0.781250
12 0.806818 0.564516 1.000000 0.140625
13 0.073864 0.639785 0.683908 0.848958
14 0.181818 0.666667 0.166667 0.083333
15 0.329545 0.661290 0.551724 0.213542
16 0.937500 0.118280 0.637931 0.000000
17 0.250000 0.860215 0.275862 0.177083
18 0.460227 0.591398 0.011494 0.901042
19 0.346591 0.440860 0.683908 0.734375
在上面的输出中,我们可以推断出每一列的最小值被转化为 0,每一列的最大值被转化为 1。
归一化后的列 A 是可视化的,如下图所示。
# %matplotlib inline
df_minmax_norm["A"].plot(kind="bar")
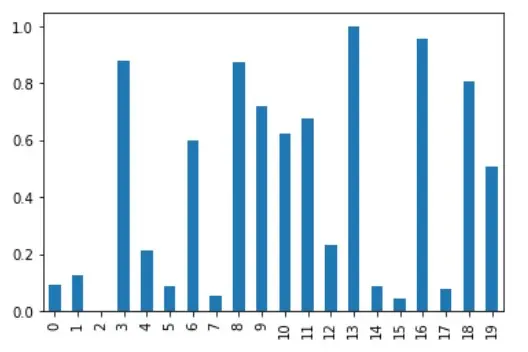
虽然这对近距离的 DataFrame 很有好处,但 MinMax 归一化可能不适合有许多异常值的 DataFrame。
使用 分位数 归一化对 Pandas DataFrame 进行归一化
量子化归一化用于高维数据分析。它观察并假设每一列的统计分布是相同的。分位数归一化包括以下步骤。
- 对每列内的数值进行排序(Ranking); 2。
- 每行的平均值,用平均值代替行中每个元素的值。
- 将数值重新排序到最初的顺序。
import numpy as np
import pandas as pd
np.random.seed(0)
df = pd.DataFrame(np.random.randint(-100, 100, size=(20, 4)), columns=list("ABCD"))
def quantile_norm(df_input):
sorted_df = pd.DataFrame(
np.sort(df_input.values, axis=0), index=df_input.index, columns=df_input.columns
)
mean_df = sorted_df.mean(axis=1)
mean_df.index = np.arange(1, len(mean_df) + 1)
quantile_df = df_input.rank(method="min").stack().astype(int).map(mean_df).unstack()
return quantile_df
df_quantile_norm = quantile_norm(df)
print(df_quantile_norm)
4.输出。
A B C D
0 77.00 -58.25 8.25 77.00
1 -36.50 92.00 -10.50 -79.25
2 -90.00 -66.50 -20.00 -20.00
3 24.75 44.00 -36.50 92.00
4 -66.50 -36.50 71.75 -3.00
5 -3.00 71.75 -73.00 -10.50
6 -20.00 -90.00 54.00 8.25
7 92.00 -41.00 77.00 77.00
8 8.25 -10.50 87.00 -58.25
9 54.00 54.00 44.00 44.00
10 -79.25 87.00 -90.00 71.75
11 44.00 -73.00 -66.50 24.75
12 71.75 -3.00 92.00 -66.50
13 -73.00 18.00 24.75 31.75
14 -58.25 31.75 -58.25 -73.00
15 -10.50 24.75 -3.00 -36.50
16 87.00 -79.25 18.00 -90.00
17 -41.00 77.00 -41.00 -41.00
18 31.75 8.25 -79.25 54.00
19 8.25 -20.00 24.75 18.00
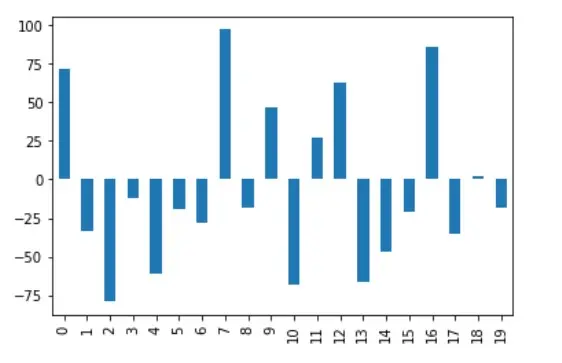
量子化归一化的输出可以直观地显示在 A 列上,如下图所示。
相关文章 - Pandas DataFrame
- 如何将 Pandas DataFrame 列标题获取为列表
- 如何删除 Pandas DataFrame 列
- 如何在 Pandas 中将 DataFrame 列转换为日期时间
- 如何在 Pandas DataFrame 中将浮点数转换为整数
- 如何按一列的值对 Pandas DataFrame 进行排序
- 如何用 group-by 和 sum 获得 Pandas 总和