Pandas 中的 GroupBy 和聚合多列数据
Fariba Laiq
2022年6月7日

Pandas 库是 Python 中一个强大的数据分析库。我们可以在 Python 中使用 Pandas 对数据框执行许多不同类型的操作。
groupby() 是一种根据特定标准将数据分成多个组的方法。之后,我们可以对分组的数据进行某些操作。
在 Pandas Python 中的多列上应用 groupby() 和 aggregate() 函数
有时我们需要对来自多个列的数据进行分组并应用一些 aggregate() 方法。aggregate() 方法是那些将多行的值组合并返回单个值的方法,例如 count()、size()、mean()、sum()、mean() 等
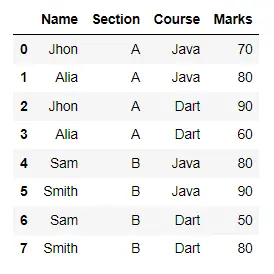
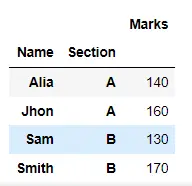
在以下代码中,我们的学生数据包含某些列的冗余值。如果你想根据学生的姓名和部门对数据进行分组以获得他们的总分,我们将根据名称和部门对数据进行分组,然后使用 aggregate() 方法计算总分。
我们已经存储了返回的结果并显示了它。
示例代码:
# Python 3.x
import pandas as pd
student = {
"Name": ["Jhon", "Alia", "Jhon", "Alia", "Sam", "Smith", "Sam", "Smith"],
"Section": ["A", "A", "A", "A", "B", "B", "B", "B"],
"Course": ["Java", "Java", "Dart", "Dart", "Java", "Java", "Dart", "Dart"],
"Marks": [70, 80, 90, 60, 80, 90, 50, 80],
}
df = pd.DataFrame(student)
display(df)
result = df.groupby(["Name", "Section"]).aggregate("sum")
display(result)
输出:
我们还可以一次执行多个聚合操作。我们会将操作名称列表传递给 aggregate() 方法。
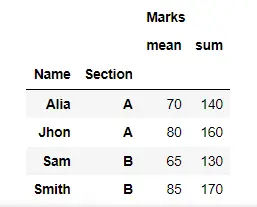
在这里,我们通过传递操作名称列表,使用 aggregate() 方法一次计算学生的平均分和总分。
示例代码:
# Python 3.x
import pandas as pd
student = {
"Name": ["Jhon", "Alia", "Jhon", "Alia", "Sam", "Smith", "Sam", "Smith"],
"Section": ["A", "A", "A", "A", "B", "B", "B", "B"],
"Course": ["Java", "Java", "Dart", "Dart", "Java", "Java", "Dart", "Dart"],
"Marks": [70, 80, 90, 60, 80, 90, 50, 80],
}
df = pd.DataFrame(student)
display(df)
result = df.groupby(["Name", "Section"]).aggregate(["mean", "sum"])
display(result)
输出:
作者: Fariba Laiq

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn