Pandas 通过 Groupby 应用变换
-
Python 中
apply()和transform()的区别 -
在 Python Pandas 中使用
apply()方法 -
在 Python Pandas 中使用
transform()方法
groupby() 是 Python 中一个强大的方法,它允许我们根据某些标准将数据分成不同的组。目的是运行计算并执行更好的分析。
Python 中 apply() 和 transform() 的区别
apply() 和 transform() 是与 groupby() 方法调用结合使用的两种方法。这两种方法的区别在于传递的参数和返回的值。
apply() 方法接受参数作为 DataFrame 并返回 DataFrame 的标量 或序列。因此,它允许我们对每个组的列、行和完整的 DataFrame 进行操作。
transform() 方法仅接受参数作为表示每个组中的列的系列,并返回与输入系列长度相同的序列。因此,我们一次只能对每个组内的特定列进行操作。
在 Python Pandas 中使用 apply() 方法
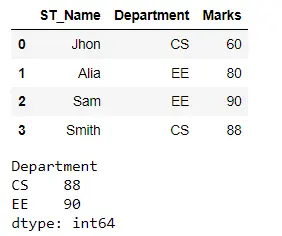
在以下代码中,我们加载了一个包含学生记录的 CSV 文件。我们使用 apply 函数来显示每个部门中的最高分数。
首先,我们必须使用 groupby() 方法对每个部门进行分组。然后使用 max() 函数找到每个部门的最高分。
输出以系列的形式返回。我们还可以对多列或整个 DataFrame 执行操作。
# Python 3.x
import pandas as pd
df = pd.read_csv("Student.csv")
display(df)
def f(my_df):
return my_df.Marks.max()
df.groupby("Department").apply(f)
输出:
_apply()-in-Python-Pandas.webp)
在 Python Pandas 中使用 transform() 方法
在下一个示例中,我们通过使用 groupby() 方法将每个部门分组,将另一列 Mean_Marks 合并到 DataFrame 中,然后使用 mean 关键字计算两个部门的平均值。
输出显示两个部门的平均分数。
在这里,transform() 方法在单个列上运行,在我们的例子中是 Marks。
# Python 3.x
import pandas as pd
df = pd.read_csv("Student.csv")
display(df)
df["Mean_Marks"] = df.groupby("Department")["Marks"].transform("mean")
display(df)
输出:
_transform()-in-Python-Pandas.webp)

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn