将函数应用于 Pandas DataFrame 中的每一行
-
Pandas
apply()函数的基本语法 -
将
lambda函数应用于 PandasDataFrame中的每一行 -
将
NumPy函数应用于 PandasDataFrame的每一行 -
使用参数将用户定义的函数应用于 Pandas
DataFrame的每一行 -
将用户定义的函数应用于每行 Pandas
DataFrame无参数
Pandas 是一个 Python 库,它提供了大量的类和函数,用于以更简单的方式执行数据分析和操作任务。我们以行和列的形式操作 Pandas DataFrame 中的数据。因此,大多数时候,我们需要对每一行或每一列应用适当的函数,以获得想要的结果。
本文将探讨如何使用 Pandas 将函数应用于 Pandas DataFrame 中的每一行。此外,我们将演示如何将各种函数(例如 lambda 函数、用户定义函数和 NumPy 函数)应用于 Pandas DataFrame 中的每一行。
Pandas apply() 函数的基本语法
以下基本语法用于应用 Pandas apply() 函数:
DataFrame.apply(function, axis, args=())
参见上面的语法中,函数被应用到每一行。axis 是函数在 DataFrame 中应用的参数。默认情况下,axis 值为 0。axis=1 的值,如果函数适用于每一行。args 表示传递给函数的元组或参数列表。
使用 pandas apply() 函数,我们可以轻松地将不同的函数应用于 DataFrame 中的每一行。以下列出的方法可帮助我们实现这一目标:
将 lambda 函数应用于 Pandas DataFrame 中的每一行
为了将 lambda 函数应用于 DataFrame 中的每一行,我们使用 lambda 函数作为 DataFrame 中的第一个参数,并将 axis=1 作为 DataFrame 中的第二个参数传递。apply() 使用上面创建的 DataFrame。
要了解如何将 lambda 函数应用于 DataFrame 中的每一行,请尝试以下示例:
示例代码:
import pandas as pd
import numpy as np
from IPython.display import display
# List of Tuples data
data = [
(1, 34, 23),
(11, 31, 11),
(22, 16, 21),
(33, 32, 22),
(44, 33, 27),
(55, 35, 11),
]
# Create a DataFrame object
dataframe = pd.DataFrame(data, columns=list("ABC"))
print("Original Dataframe before applying lambda function: ", sep="\n")
display(dataframe)
# Apply a lambda function to each row by adding 10
new_dataframe = dataframe.apply(lambda x: x + 10, axis=1)
print("Modified New Dataframe by applying lambda function on each row:")
display(new_dataframe)
输出:
Original Dataframe before applying lambda function:
A B C
0 1 34 23
1 11 31 11
2 22 16 21
3 33 32 22
4 44 33 27
5 55 35 11
Modified Dataframe by applying lambda function on each row:
A B C
0 11 44 33
1 21 41 21
2 32 26 31
3 43 42 32
4 54 43 37
5 65 45 21

将 NumPy 函数应用于 Pandas DataFrame 的每一行
我们还可以使用作为参数传递给 dataframe.apply() 的 NumPy 函数。在以下示例中,我们将 NumPy 函数应用于每一行并计算每个值的平方根。
示例代码:
import pandas as pd
import numpy as np
from IPython.display import display
def main():
# List of Tuples
data = [
(2, 3, 4),
(3, 5, 10),
(44, 16, 2),
(55, 32, 12),
(60, 33, 27),
(77, 35, 11),
]
# Create a DataFrame object
dataframe = pd.DataFrame(data, columns=list("ABC"))
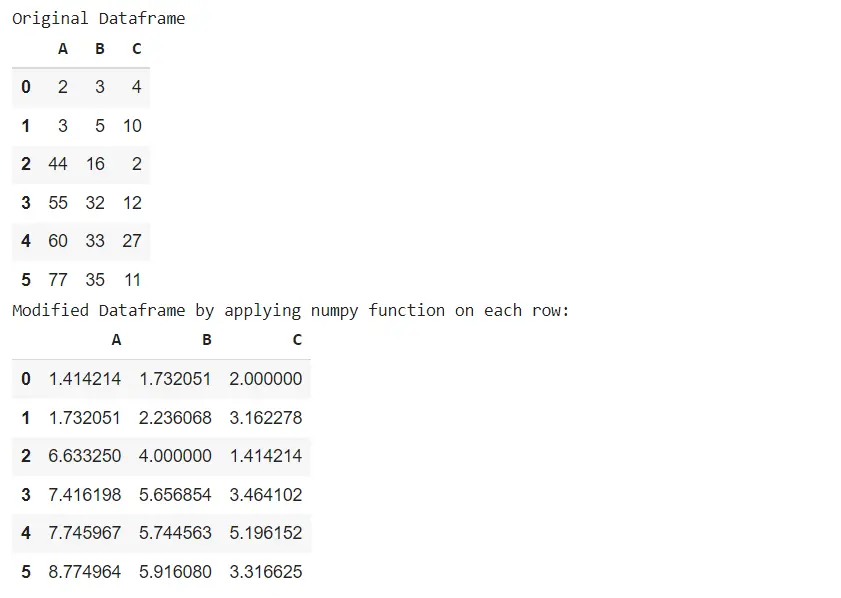
print("Original Dataframe", sep="\n")
display(dataframe)
# Apply a numpy function to every row by taking square root of each value
new_dataframe = dataframe.apply(np.sqrt, axis=1)
print("Modified Dataframe by applying numpy function on each row:", sep="\n")
display(new_dataframe)
if __name__ == "__main__":
main()
输出:
Original Dataframe
A B C
0 2 3 4
1 3 5 10
2 44 16 2
3 55 32 12
4 60 33 27
5 77 35 11
Modified Dataframe by applying numpy function on each row:
A B C
0 1.414214 1.732051 2.000000
1 1.732051 2.236068 3.162278
2 6.633250 4.000000 1.414214
3 7.416198 5.656854 3.464102
4 7.745967 5.744563 5.196152
5 8.774964 5.916080 3.316625
使用参数将用户定义的函数应用于 Pandas DataFrame 的每一行
我们还可以将 user defined 函数作为带有一些参数的 dataframe.apply 中的参数传递。在下面的例子中,我们传递了一个用户定义的函数,参数为 args=[2]。每个行值系列乘以 2。
请参阅以下示例:
示例代码:
import pandas as pd
import numpy as np
from IPython.display import display
def multiplyData(x, y):
return x * y
def main():
# List of Tuples
data = [
(2, 3, 4),
(3, 5, 10),
(44, 16, 2),
(55, 32, 12),
(60, 33, 27),
(77, 35, 11),
]
# Create a DataFrame object
dataframe = pd.DataFrame(data, columns=list("ABC"))
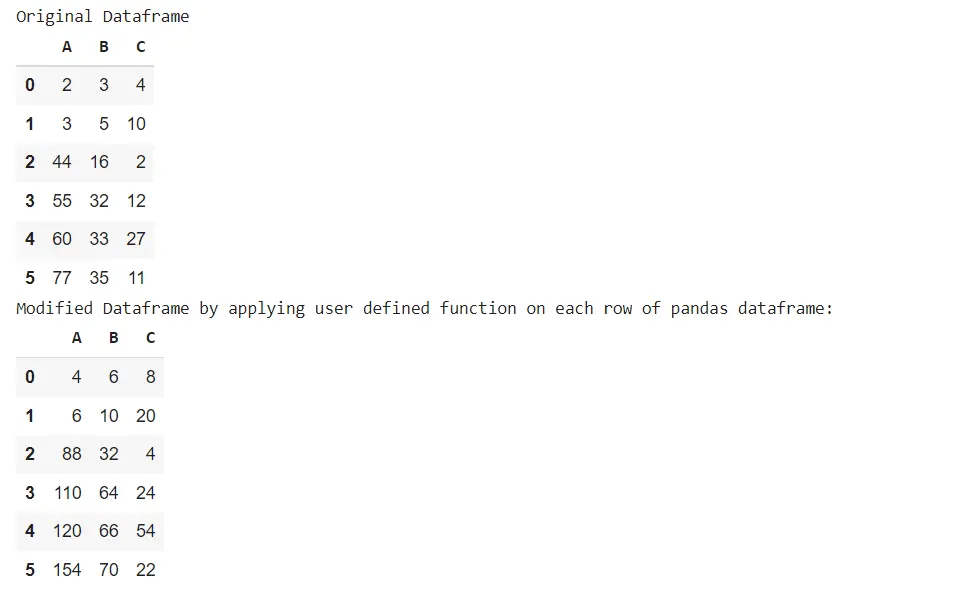
print("Original Dataframe", sep="\n")
display(dataframe)
# Apply a user defined function with arguments to each row of Pandas dataframe
new_dataframe = dataframe.apply(multiplyData, axis=1, args=[2])
print(
"Modified Dataframe by applying user defined function on each row of pandas dataframe:",
sep="\n",
)
display(new_dataframe)
if __name__ == "__main__":
main()
输出:
Original Dataframe
A B C
0 2 3 4
1 3 5 10
2 44 16 2
3 55 32 12
4 60 33 27
5 77 35 11
Modified Dataframe by applying user defined function on each row of pandas dataframe:
A B C
0 4 6 8
1 6 10 20
2 88 32 4
3 110 64 24
4 120 66 54
5 154 70 22
将用户定义的函数应用于每行 Pandas DataFrame 无参数
我们还可以在没有任何参数的情况下将用户定义的函数应用于每一行。请参阅以下示例:
示例代码:
import pandas as pd
import numpy as np
from IPython.display import display
def userDefined(x):
return x * 4
def main():
# List of Tuples
data = [
(2, 3, 4),
(3, 5, 10),
(44, 16, 2),
(55, 32, 12),
(60, 33, 27),
(77, 35, 11),
]
# Create a DataFrame object
dataframe = pd.DataFrame(data, columns=list("ABC"))
print("Original Dataframe", sep="\n")
display(dataframe)
# Apply a user defined function without arguments to each row of Pandas dataframe
new_dataframe = dataframe.apply(userDefined, axis=1)
print(
"Modified Dataframe by applying user defined function on each row of pandas dataframe:",
sep="\n",
)
display(new_dataframe)
if __name__ == "__main__":
main()
输出:
Original Dataframe
A B C
0 2 3 4
1 3 5 10
2 44 16 2
3 55 32 12
4 60 33 27
5 77 35 11
Modified Dataframe by applying user defined function on each row of pandas dataframe:
A B C
0 8 12 16
1 12 20 40
2 176 64 8
3 220 128 48
4 240 132 108
5 308 140 44
