在 Pandas DataFrame 中过滤数据
Fariba Laiq
2024年2月15日
本教程将演示基于单个或多个条件过滤 Pandas DataFrame 中的数据。
布尔索引意味着选择数据子集或根据某些条件过滤数据。我们处理 DataFrame 中数据的实际值,而不是它们的行或列标签或整数位置。
布尔向量用于过滤布尔索引中的数据。括号可用于对涉及运算符的多个条件进行分组,例如| (OR)、& (AND)、== (EQUAL) 和 ~ (NOT)。
基于单一条件过滤 Pandas DataFrame 中的数据
我们可以通过应用单个条件来使用单个列的值过滤数据。
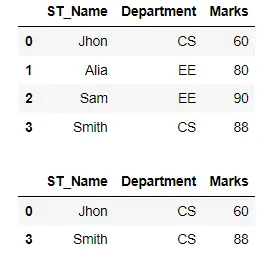
在下面的代码中,我们有学生的数据,我们通过将单个条件应用于 Department 值来过滤记录。只有那些系为 CS 的学生的记录才会显示。
示例代码:
# Python 3.x
import pandas as pd
df = pd.read_csv("Student.csv")
display(df)
df_filtered = df[(df["Department"] == "CS")]
display(df_filtered)
输出:
根据多个条件过滤 Pandas DataFrame 中的数据
在某些情况下,我们还可以应用多个条件从单个列中选择数据。
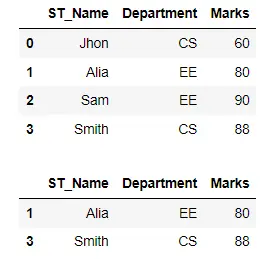
如果我们只想显示那些分数大于 60 但小于 90 的学生的记录,我们将使用由 & 运算符连接的多个条件。
要记住的重要一点是分别使用运算符&、|、~而不是 AND、OR、NOT。
示例代码:
# Python 3.x
import pandas as pd
df = pd.read_csv("Student.csv")
display(df)
df_filtered = df[(df["Marks"] > 60) & (df["Marks"] < 90)]
display(df_filtered)
输出:
根据多列值过滤 Pandas DataFrame 中的数据
我们还可以使用基于多列值的条件过滤数据。
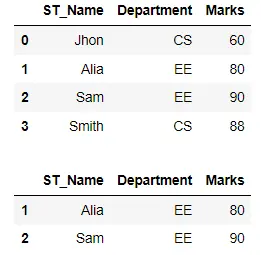
在下面的代码中,我们过滤了记录,只显示部门为 EE 且标记高于或等于 80 的记录。我们使用括号对多个条件进行分组。
每当我们过滤来自多个列的数据时,我们总是应用多个条件。
示例代码:
# Python 3.x
import pandas as pd
df = pd.read_csv("Student.csv")
display(df)
df_filtered = df[(df["Department"] == "EE") & (df["Marks"] >= 80)]
display(df_filtered)
输出:
作者: Fariba Laiq

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn