填充 Pandas DataFrame 中的缺失值

有时,我们可能有一个缺失值的数据集。有很多方法可以使用某些方法来替换丢失的数据。
ffill()(前向填充)是替换 DataFrame 中缺失值的方法之一。此方法将 NaN 替换为先前的行或列值。
Pandas 中 ffill() 方法的语法
# Python 3.x
dataframe.ffill(axis, inplace, limit, downcast)
ffill() 方法采用四个可选参数:
axis指定从何处填充缺失值。值 0 表示行,1 表示列。inplace可以是 True 或 False。True 指定在当前 DataFrame 中进行更改,而 False 表示创建具有填充值的新 DataFrame 的单独副本。limit指定要沿轴连续填充的最大缺失值数。downcast指定要为特定数据类型填充的值字典。
使用 Pandas 中的 ffill() 方法填充 DataFrame 中的缺失值
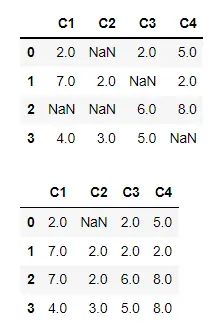
沿行轴填充缺失值
在下面的代码中,我们有一个缺失值用 None 或 NaN 表示的 DataFrame。我们已经显示了实际的 DataFrame,然后将 ffill() 方法应用于该 DataFrame。
默认情况下,ffill() 方法会沿着行/索引轴替换缺失值。NaN 将替换为该单元格上一行的值。
第一行在输出中仍然包含 NaN,因为没有前一行。
示例代码:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"C1": [2, 7, None, 4],
"C2": [None, 2, None, 3],
"C3": [2, None, 6, 5],
"C4": [5, 2, 8, None],
}
)
display(df)
df2 = df.ffill()
display(df2)
输出:
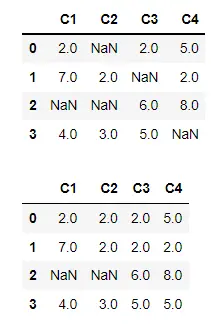
沿列轴填充缺失值
在这里,我们将指定 axis=1。它将通过观察相应单元格的前一列中的值来填充缺失值。
在输出中,除了两个值之外,所有值都被填充。因为我们没有列 1 的前一列,所以该值仍然是 NaN。
第 2 列中的值是 NaN,因为前一列中对应的单元格也是 NaN。
示例代码:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"C1": [2, 7, None, 4],
"C2": [None, 2, None, 3],
"C3": [2, None, 6, 5],
"C4": [5, 2, 8, None],
}
)
display(df)
df2 = df.ffill(axis=1)
display(df2)
输出:
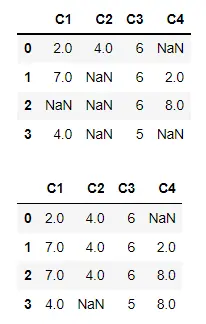
使用 limit 限制要填充的连续 NaN 的数量
我们可以使用 limit 参数来限制沿行或列轴填充的连续缺失值的数量。
在下面的代码中,我们有实际的 DataFrame,其中最后三行有连续的 NaN。如果我们指定 limit=2,则不能超过两个连续的 NaN 可以沿行轴填充。
这就是为什么最后一行中的 NaN 仍未填充的原因。
示例代码:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"C1": [2, 7, None, 4],
"C2": [4, None, None, None],
"C3": [6, 6, 6, 5],
"C4": [None, 2, 8, None],
}
)
display(df)
df2 = df.ffill(axis=0, limit=2)
display(df2)
输出:
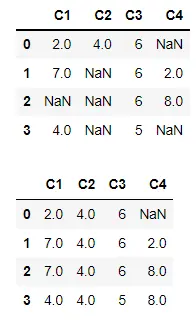
使用 inplace 填充原始 DataFrame 中的值
假设我们想要在原始 DataFrame 中进行更改,而不是在另一个 DataFrame 中复制具有填充值的 DataFrame。在这种情况下,我们可以使用值为 True 的 inplace 参数。
示例代码:
# Python 3.x
import pandas as pd
df = pd.DataFrame(
{
"C1": [2, 7, None, 4],
"C2": [4, None, None, None],
"C3": [6, 6, 6, 5],
"C4": [None, 2, 8, None],
}
)
display(df)
df.ffill(inplace=True)
display(df)
输出:

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn