更改 Pandas DataFrame 列的顺序
Pandas DataFrame 是二维数据结构,以行和列的形式存储信息。
使用 reindex() 函数更改 Python Pandas Dataframe 列的顺序
pandas 中的 reindex() 函数可用于重新排序或重新排列 DataFrame 的列。我们将以所需的顺序创建一个新的列列表,然后使用 data= data[cols] 以这个新顺序重新排列列。
首先,我们需要导入 python 库 numpy 和 pandas。然后声明一个变量 data,我们在其中使用 np.random.rand(10, 5) 函数创建一个 5 列和 10 行的 DataFrame。
此函数创建随机值以使 DataFrame 具有以下 DataFrame:
import pandas as pd
import numpy as np
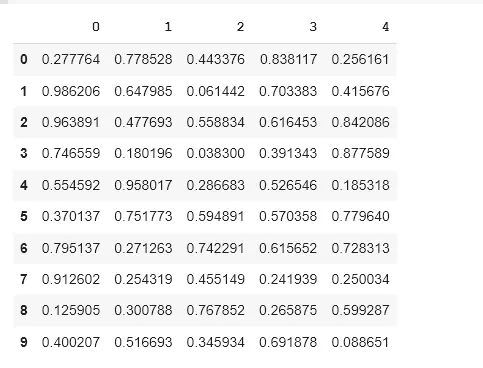
data = pd.DataFrame(np.random.rand(10, 5))
data
输出:
0 1 2 3 4
0 0.277764 0.778528 0.443376 0.838117 0.256161
1 0.986206 0.647985 0.061442 0.703383 0.415676
2 0.963891 0.477693 0.558834 0.616453 0.842086
3 0.746559 0.180196 0.038300 0.391343 0.877589
4 0.554592 0.958017 0.286683 0.526546 0.185318
5 0.370137 0.751773 0.594891 0.570358 0.779640
6 0.795137 0.271263 0.742291 0.615652 0.728313
7 0.912602 0.254319 0.455149 0.241939 0.250034
8 0.125905 0.300788 0.767852 0.265875 0.599287
9 0.400207 0.516693 0.345934 0.691878 0.088651
通过分配,添加另一列:使用以下代码,因此该列计算上面创建的 DataFrame 的 mean 值。
data["mean"] = data.mean(1)
data
输出:
上面的输出显示了第 6 列的平均值。我们如何将列均值移到前面,即,使其成为第一列,同时保持其他列的原始顺序?
一种直接的解决方案是使用列列表重新分配 DataFrame,然后可以根据需要对其进行重构。columns.tolist() 函数在列表中列出列的名称。
columns_name = data.columns.tolist()
columns_names
输出:
[0, 1, 2, 3, 4, 'mean']
根据需要重新排列 cols。这就是我们如何让最后一个元素到达顶部:
columns = columns_name[-1:] + columns_name[:-1]
columns
输出:
['mean', 0, 1, 2, 3, 4]
上面的输出显示平均列移动到第一个。同样,我们更改索引值以首先更改没有 4 个位置的列。
columns = columns_name[-2:] + columns_name[:-3]
columns
输出:
[4, 'mean', 0, 1, 2]
如你所见,第 4 列移动到第 1 列和第 1 列,这意味着移动到第 2 位置。这就是我们改变列顺序的方式。
现在我们使用 reindex() 函数对 python DataFrame 的列进行重新排序。你还可以使用列名列表并将该列表传递给 reindex() 方法,如下所示。
使用 reindex() 函数重新排序。reindex() 方法将列作为列表接受。
带有列名的单个大括号用于按名称更改列顺序。
column_names = [0, 2, 3, 1, 4, "mean"]
data = data.reindex(columns=column_names)
data
输出:
0 2 3 1 4 mean
0 0.277764 0.443376 0.838117 0.778528 0.256161 0.518789
1 0.986206 0.061442 0.703383 0.647985 0.415676 0.562938
2 0.963891 0.558834 0.616453 0.477693 0.842086 0.691791
3 0.746559 0.038300 0.391343 0.180196 0.877589 0.446797
4 0.554592 0.286683 0.526546 0.958017 0.185318 0.502231
5 0.370137 0.594891 0.570358 0.751773 0.779640 0.613360
6 0.795137 0.742291 0.615652 0.271263 0.728313 0.630531
7 0.912602 0.455149 0.241939 0.254319 0.250034 0.422809
8 0.125905 0.767852 0.265875 0.300788 0.599287 0.411942
9 0.400207 0.345934 0.691878 0.516693 0.088651 0.408673
上面的输出显示你可以通过使用列名索引 DataFrame 并创建新 DataFrame 来重新排列列。
然后按索引名称按索引值使用 reindex()。对索引名称使用双括号。
data = data[[1, 0, 2, 3, 4, "mean"]]
data
输出:
1 0 2 3 4 mean
0 0.778528 0.277764 0.443376 0.838117 0.256161 0.518789
1 0.647985 0.986206 0.061442 0.703383 0.415676 0.562938
2 0.477693 0.963891 0.558834 0.616453 0.842086 0.691791
3 0.180196 0.746559 0.038300 0.391343 0.877589 0.446797
4 0.958017 0.554592 0.286683 0.526546 0.185318 0.502231
5 0.751773 0.370137 0.594891 0.570358 0.779640 0.613360
6 0.271263 0.795137 0.742291 0.615652 0.728313 0.630531
7 0.254319 0.912602 0.455149 0.241939 0.250034 0.422809
8 0.300788 0.125905 0.767852 0.265875 0.599287 0.411942
9 0.516693 0.400207 0.345934 0.691878 0.088651 0.408673
结论
我们已经知道如何使用 reindex() 方法和 DataFrame 索引对 DataFrame 列重新排序,并按字母顺序按升序或降序对列进行排序。
此外,我们还发现了如何将列移动到第一个、最后一个或特定位置。这些操作可以在 pandas DataFrame 中用于执行各种数据操作操作。