删除 MySQL 中的重复行
本文将向你展示在 MySQL 中删除表中存在的重复行的多种方法。有四种不同的方法来完成这项任务。
- 使用
DELETE JOIN语句删除重复行 - 使用嵌套查询删除重复行
- 使用临时表删除重复行
- 使用
ROW_NUMBER()函数删除重复行
以下脚本创建一个包含四列(custid、first_name、last_name 和 email)的表 customers。
CREATE TABLE customers (custid INT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, email VARCHAR(255) NOT NULL );
CREATE TABLE customers (custid INT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, email VARCHAR(255) NOT NULL );
将示例数据值插入 customers 表以进行演示。
INSERT INTO customers
VALUES (110,'Susane','Mathew','sussane.mathew@gmail.com'),
(124,'Jean','Carl','jean.carl@gmail.com'),
(331,'Peter','cohelo','peter.coh@google.com'),
(114,'Jaine','Lora','jaine.l@abs.com'),
(244,'Junas','sen','jonas.sen@mac.com');
INSERT INTO customers
VALUES (113,'Jaine','Lora','jaine.l@abs.com'),
(111,'Susane','Mathew','sussane.mathew@gmail.com'),
(665,'Roma','Shetty','roma.sh11@yahoo.com'),
(997,'Beatrice','shelon','beatrice.ss22@yahoo.com'),
(332,'Peter','cohelo','peter.coh@google.com');
下面是从 customers 表返回所有数据的给定查询:
SELECT * FROM customers order by custid;
为了从表中查找重复记录,我们将在 customers 表中执行下面提到的查询。
SELECT custid, COUNT(custid) FROM customers GROUP BY custid HAVING COUNT(custid) > 1;
如你所见,我们的结果中有三行具有重复的客户 ID。
使用 DELETE JOIN 语句删除重复行
使用 INNER JOIN 和 delete statement 允许你从 MySQL 的表中删除重复的行。
以下查询通过选择具有最低客户 ID 的重复记录的所有行来使用嵌套查询的概念。找到后,我们将删除这些具有最低 custid 的重复记录:
Delete from customers where custid IN (Select c1.custid FROM customers as c1
INNER JOIN customers as c2 ON c1.custid < c2.custid AND c1.email = c2.email);
在这个查询中客户表被引用了两次;因此,它使用别名 c1 和 c2。
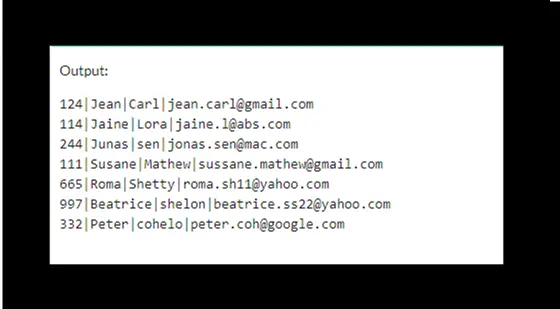
输出将是:
它表示已删除三行。
SELECT custid, COUNT(custid) FROM customers GROUP BY custid HAVING COUNT(custid) > 1;
现在,此查询返回一个空集,这意味着重复的行已被删除。
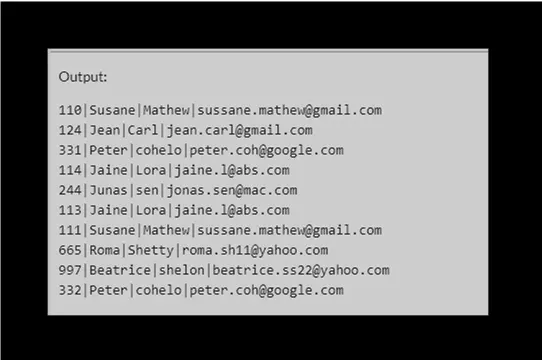
我们可以使用 select 查询来验证 customers 表中的数据:
SELECT * FROM customers;
如果你希望删除重复的行并保留最低的 custid,那么你可以使用相同的查询,但条件略有不同,如以下语句所示:
Delete from customers where custid IN (Select c1.custid FROM customers as c1
INNER JOIN customers as c2 ON c1.custid > c2.custid AND c1.email = c2.email);
以下输出显示了删除重复行后 customers 表的数据。
使用嵌套查询删除重复行
现在让我们看一下使用嵌套查询删除重复行的分步过程。这是解决问题的一种比较直接的方法。
首先,我们将使用此查询从表中选择唯一记录。
Select * from (select max(custid) from customers group by email);
然后我们将使用带有 where 子句的 delete 查询,如下所示,删除表中的重复行。
Delete from customers where custid not in
(select * from (select max(custid) from customers group by email));
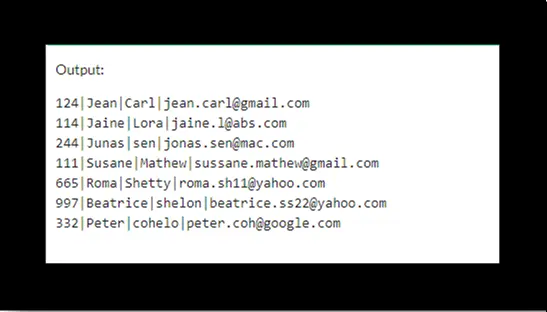
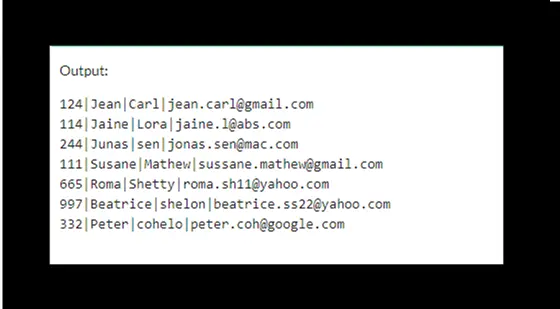
输出将是:
使用临时表删除重复行
现在让我们看一下使用临时表删除重复行的分步过程:
- 首先,你需要创建一个与原表结构相同的新表。
- 现在,将原始表中的不同行插入到临时表中。
- 删除原表,将临时表重命名为原表。
第 1 步:使用 CREATE TABLE 和 LIKE 关键字创建表
复制整个表结构的语法如下所示。
CREATE TABLE destination_table LIKE source;
因此,假设我们有相同的客户表,我们将编写下面给出的查询。
CREATE TABLE temporary LIKE customers;
步骤 2. 在临时表中插入行
下面给出的查询从客户复制唯一行并将其写入临时表。在这里,我们按电子邮件分组。
INSERT INTO temporary SELECT * FROM customers GROUP BY email;
步骤 3. 删除原始客户表并通过将其重命名为客户来创建一个临时表作为原始表。
DROP TABLE customers;
ALTER TABLE temporary RENAME TO customers;
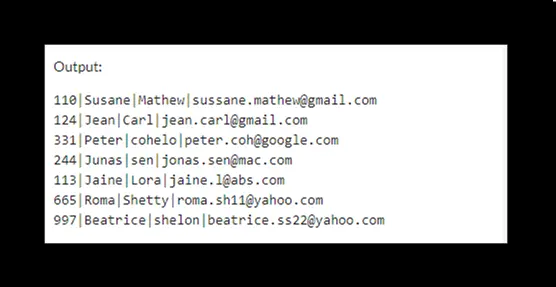
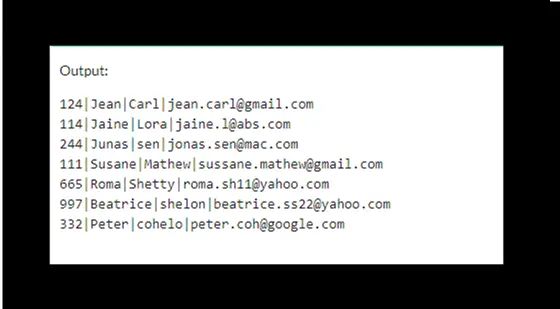
输出将是:
这种方法很耗时,因为它需要更改表的结构,而不仅仅是处理数据值。
使用 ROW_NUMBER() 函数删除重复行
ROW_NUMBER() 函数已在 MySQL 8.02 版中引入。因此,如果你运行的是高于 8.02 的 MySQL 版本,则可以采用这种方法。
此查询使用 ROW_NUMBER() 函数为每一行分配一个数值。在重复电子邮件的情况下,行号将大于一。
SELECT custid, email, ROW_NUMBER() OVER ( PARTITION BY email ORDER BY email ) AS row FROM customers;
上面的代码片段返回重复行的 id 列表:
SELECT custid
FROM ( SELECT custid, ROW_NUMBER() OVER (PARTITION BY email ORDER BY email) AS row FROM customers) t WHERE row > 1;
一旦我们获得具有重复值的客户列表,我们可以使用 delete 语句在 where 子句中使用子查询删除它,如下所示。
DELETE FROM customers
WHERE custid IN
(SELECT custid FROM
(SELECT custid, ROW_NUMBER() OVER
(PARTITION BY email ORDER BY email) AS row FROM customers) t
WHERE row > 1);
输出将是: