Pandas DataFrame DataFrame.to_csv() 函数
Minahil Noor
2023年1月30日
-
pandas.DataFrame.to_csv()语法 -
示例代码:
DataFrame.to_csv() -
示例代码:
DataFrame.to_csv()为 CSV 数据指定分隔符 -
示例代码:
DataFrame.to_csv()选择少数几列并重新命名列
Python Pandas DataFrame.to_csv() 函数将一个 DataFrame 的行和列所包含的值保存到一个 CSV 文件中。我们也可以将 DataFrame 转换为 CSV 字符串。
pandas.DataFrame.to_csv() 语法
DataFrame.to_csv(
path_or_buf=None,
sep=",",
na_rep="",
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
mode="w",
encoding=None,
compression="infer",
quoting=None,
quotechar='""',
line_terminator=None,
chunksize=None,
date_format=None,
doublequote=True,
escapechar=None,
decimal=".",
)
参数
这个函数有几个参数。上面提到了所有参数的默认值。
path_or_buf |
它是一个字符串或文件句柄。它代表一个文件或一个文件对象的名称。如果它的值是 None,那么 DataFrame 将被转换为 CSV “string”。 |
sep |
它是一 Series 个字符串。它代表 CSV 文件中使用的分隔符。 |
na_rep |
它是一个字符串。它代表缺失的数据。 |
float_format |
它是一个字符串。它表示浮点数的格式。 |
columns |
它是一个 Series。它表示将保存在 CSV 文件中的 DataFrame 的列。 |
header |
它是一个布尔值或一个字符串列表。如果它的值被设置为 False,那么列名就不会保存在 CSV 文件中。如果传递一个字符串列表,那么这些字符串将作为列名保存。 |
index |
它是一个布尔值,如果它的值是 True,则保存行名,即索引。如果它的值为 True,那么行名即索引将被保存。 |
index_label |
它是一个字符串或 Series。它代表一个特定索引的列名。 |
mode |
它是一个字符串。它代表进程的模式。由于我们正在将 DataFrame 写入 CSV 文件,它的值是 Python 写入模式 w。 |
encoding |
它是一个字符串。它代表 CSV 文件中要使用的编码方案,默认的编码方案是 utf-8。默认的编码方案是 utf-8。 |
compression |
它是一个字符串或字典。如果是字符串,则代表压缩模式。如果它是一个字典,那么 method 键对应的值代表压缩模式。它有几种压缩模式。你可以查看这里。 |
quoting |
它代表一个 CSV 模块的常量 |
quotechar |
它是一个字符串,长度为 1。它的长度为 1,表示用于引用字段的字符。 |
line_terminator |
它是一个字符串。它代表 CSV 文件中新行的字符。 |
chunksize |
它是一个整数。它表示每次要写入 CSV 文件的行数。 |
date_format |
它是一个字符串。它代表 DateTime 对象的格式。 |
doublequote |
它是一个布尔值。它控制 quotechar 的引用。 |
escapechar |
它是一个字符串,长度为 1。它的长度为 1,代表用于转义的 sep 和 quotechar 的字符。 |
decimal |
它是一个字符串。它代表小数点的字符。 |
返回值
它返回 None 或字符串。如果 path_or_buf 是 None,那么它将 DataFrame 转换为字符串并返回字符串。否则,它返回 None。
示例代码:DataFrame.to_csv()
在接下来的几个代码中,我们将以不同的方式实现这个函数。
import pandas as pd
dataframe=pd.DataFrame({
'Attendance':
{0: 60,
1: 100,
2: 80,
3: 78,
4: 95},
'Name':
{0: 'Olivia',
1: 'John',
2: 'Laura',
3: 'Ben',
4: 'Kevin'},
'Obtained Marks':
{0: 90,
1: 75,
2: 82,
3: 64,
4: 45}
})
print(dataframe)
示例 DataFrame 是:
Attendance Name Obtained Marks
0 60 Olivia 90
1 100 John 75
2 80 Laura 82
3 78 Ben 64
4 95 Kevin 45
这个函数的所有参数都是可选的。如果我们在执行这个函数时不传递任何参数,那么它将产生以下输出。
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": {0: 60, 1: 100, 2: 80, 3: 78, 4: 95},
"Name": {0: "Olivia", 1: "John", 2: "Laura", 3: "Ben", 4: "Kevin"},
"Obtained Marks": {0: 90, 1: 75, 2: 82, 3: 64, 4: 45},
}
)
csvstring = dataframe.to_csv()
print(csvstring)
输出:
,Attendance,Name,Obtained Marks
0,60,Olivia,90
1,100,John,75
2,80,Laura,82
3,78,Ben,64
4,95,Kevin,45
该函数使用所有默认值生成了输出。它返回了一个 CSV 字符串。现在我们将把数据保存在 CSV 文件中。
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": {0: 60, 1: 100, 2: 80, 3: 78, 4: 95},
"Name": {0: "Olivia", 1: "John", 2: "Laura", 3: "Ben", 4: "Kevin"},
"Obtained Marks": {0: 90, 1: 75, 2: 82, 3: 64, 4: 45},
}
)
returnValue = dataframe.to_csv("myfile.csv")
print(returnValue)
输出:
None
函数在保存程序的目录下创建了一个新的 CSV 文件。
示例代码:DataFrame.to_csv() 为 CSV 数据指定分隔符
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": {0: 60, 1: 100, 2: 80, 3: 78, 4: 95},
"Name": {0: "Olivia", 1: "John", 2: "Laura", 3: "Ben", 4: "Kevin"},
"Obtained Marks": {0: 90, 1: 75, 2: 82, 3: 64, 4: 45},
}
)
returnValue = dataframe.to_csv(sep="@")
print(returnValue)
输出:
@Attendance@Name@Obtained Marks
0@60@Olivia@90
1@100@John@75
2@80@Laura@82
3@78@Ben@64
4@95@Kevin@45
示例代码:DataFrame.to_csv() 选择少数几列并重新命名列
import pandas as pd
dataframe = pd.DataFrame(
{
"Attendance": {0: 60, 1: 100, 2: 80, 3: 78, 4: 95},
"Name": {0: "Olivia", 1: "John", 2: "Laura", 3: "Ben", 4: "Kevin"},
"Obtained Marks": {0: 90, 1: 75, 2: 82, 3: 64, 4: 45},
}
)
returnValue = dataframe.to_csv(
"myfile.csv", columns=["Name", "Obtained Marks"], header=["Full Name", "Marks"]
)
print(returnValue)
输出:
None
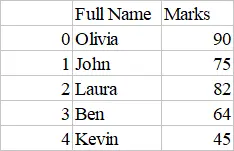
就像上面的代码一样,我们可以使用不同的参数来定制我们的 CSV 文件。这个函数提供了几个参数来使用。