Python 中的平滑資料
Shivam Arora
2023年1月30日
-
在 Python 中使用
scipy.signal.savgol_filter()方法平滑資料 -
在 Python 中使用
numpy.convolve方法平滑資料 -
在 Python 中使用
statsmodels.kernel_regression平滑資料

Python 在資料分析和視覺化方面有著廣泛的應用。當我們分析包含許多觀測值的海量資料集時,我們可能會遇到必須平滑圖形上的曲線以更仔細地研究最終圖的情況。我們將討論如何使用不同的方法在 Python 中實現這一點。
在 Python 中使用 scipy.signal.savgol_filter() 方法平滑資料
Savitzky-Golay 濾波器是一種數字濾波器,它使用資料點來平滑圖形。它使用最小二乘法建立一個小視窗並對該視窗的資料應用多項式,然後使用該多項式來假設特定視窗的中心點。接下來,將視窗移動一個資料點,並迭代該過程,直到所有鄰居彼此相對調整。
我們可以使用 scipy.signal.savgol_filter() 函式在 Python 中實現這一點。
請參考以下示例。
import numpy as np
from scipy.signal import savgol_filter
import matplotlib.pyplot as plt
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x) + np.random.random(100) * 0.2
yhat = savgol_filter(y, 51, 3)
plt.plot(x, y)
plt.plot(x, yhat, color="green")
plt.show()
輸出:
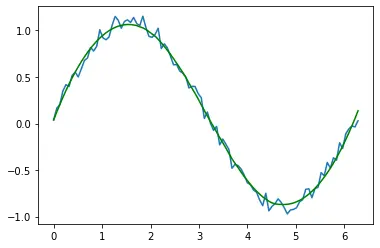
在上面的例子中,我們使用過濾方法來平滑要繪製在 y 軸上的資料。我們繪製了原始資料和平滑資料,以便你觀察差異。
在 Python 中使用 numpy.convolve 方法平滑資料
numpy.convolve() 給出兩個一維序列的離散線性卷積。我們將使用它來建立可以過濾和平滑資料的移動平均線。
這不被認為是一個好方法。
例如,
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x) + np.random.random(100) * 0.8
def smooth(y, box_pts):
box = np.ones(box_pts) / box_pts
y_smooth = np.convolve(y, box, mode="same")
return y_smooth
plt.plot(x, y)
plt.plot(x, smooth(y, 3))
plt.plot(x, smooth(y, 19))
輸出:
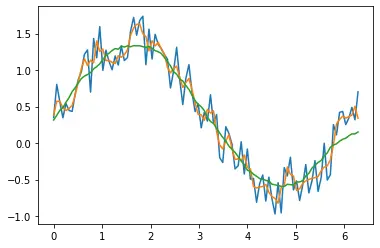
在上面的例子中,我們繪製了兩個時間增量為 3 和 19 的移動平均線。我們在圖中繪製了它們。
我們也可以使用其他方法來計算移動平均線。
在 Python 中使用 statsmodels.kernel_regression 平滑資料
核迴歸計算條件均值 E[y|X],其中 y = g(X) + e 並擬合模型。它可用於根據控制變數平滑資料。
為此,我們必須使用 statsmodels 模組中的 KernelReg() 函式。
例如,
from statsmodels.nonparametric.kernel_regression import KernelReg
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 2 * np.pi, 100)
y = np.sin(x) + np.random.random(100) * 0.2
kr = KernelReg(y, x, "c")
plt.plot(x, y, "+")
y_pred, y_std = kr.fit(x)
plt.plot(x, y_pred)
plt.show()
輸出:
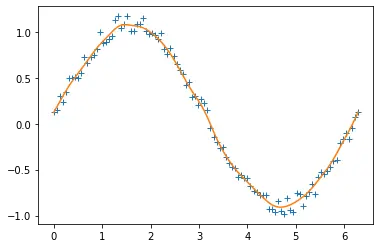
請注意,此方法產生了良好的結果,但被認為非常慢。我們也可以使用傅立葉變換,但它只適用於週期性資料。