Python 中最長的公共子字串
Python 中的字串在其中儲存了一系列字元以對它們執行各種操作。子字串是這些字串的一部分。
在本文中,我們需要找到兩個給定字串之間的最長公共子字串,並將討論相同的各種解決方案。
Python 中最長的公共子字串
子字串是給定字串中連續的字元序列。它可以是任何長度。
主要問題是我們已經獲得了兩個字串,我們需要找到一個在給定字串之間共有的子字串,並且應該是所有可能的公共子字串中最長的。
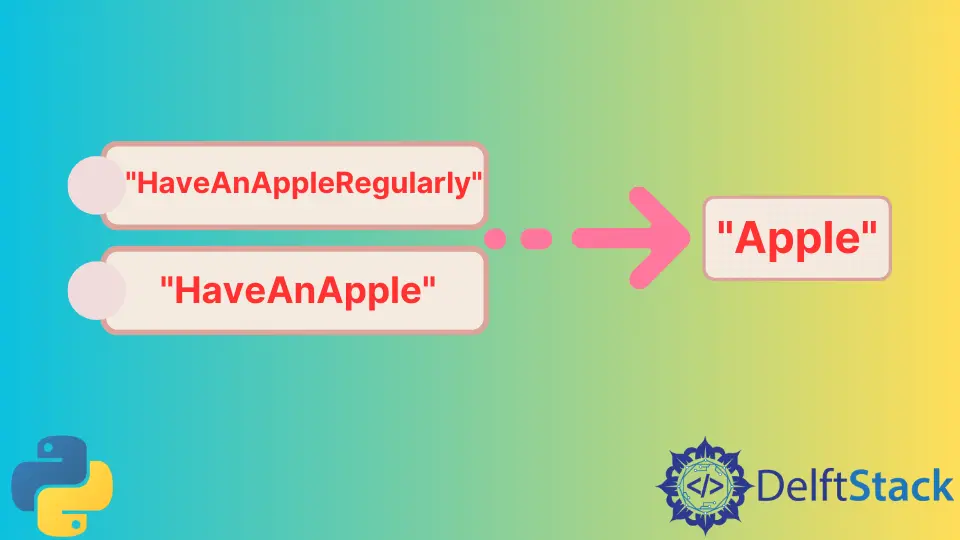
Input: str1 = "HaveAAppleRegularly"
str2 = "HaveAnAnApple"
Output: "Apple"
在上面的示例中,我們在給定字串之間有兩個公共子字串,"Have" 和 "Apple"。但由於"Apple"子字串的長度是其餘子字串中最長的;因此,它將顯示為我們的結果。
可以使用遞迴和動態規劃等各種概念來解決這個問題。
在 Python 中使用迴圈來查詢最長公共子字串
迴圈可用於遍歷字串。我們可以在這裡使用迴圈遍歷字串,並在兩個給定字串之間找到我們最長的公共子字串。
在這種方法中,我們將同時使用 for 和 while 迴圈。以下是在 Python 中查詢最長公共子字串需要遵循的步驟。
-
我們將找到第一個字串的所有子字串。
-
我們將檢查第一個字串的當前子字串也是第二個字串的子字串。
-
如果兩個子字串都匹配,那麼我們會將它們的長度儲存在某個變數中,並繼續更新該變數。
-
最後,儲存子字串長度的變數將包含我們想要的結果並被列印出來。
程式碼示例:
str1 = "PokemonGo"
str2 = "StopPokemonLetsGo"
result = 0
for i in range(len(str1)):
for j in range(len(str2)):
k = 0
while (
(i + k) < len(str1) and (j + k) < len(str2) and str1[i + k] == str2[j + k]
):
k = k + 1
result = max(result, k)
print("Length of the longest common substring is:", result)
輸出:
Length of the longest common substring is: 7
字串的所有子字串都可以在 O(n^2) 時間內計算出來,而檢查當前子字串是否與第二個字串的子字串匹配則需要 O(m) 時間。上述方法的時間複雜度為 O(n^2 * m),其中 n 和 m 分別是兩個給定字串的長度。
然而,由於我們沒有佔用任何額外的空間來實現解決方案,因此上述解決方案的空間複雜度將是 O(1)。
使用遞迴查詢最長的公共子字串
遞迴是指呼叫自身的函式。我們需要一個基本案例和遞迴問題的選擇圖。
我們將按照以下步驟查詢 Python 中最長的公共子字串。
-
在給定的尋找最長公共子字串的問題中,最小的可能輸入可以是長度為
0的字串。因此,基本情況將檢查輸入的任何長度是否為0,然後該函式應返回0。 -
現在,我們將比較兩個字串的最後一個字元,然後出現兩種情況,兩個字元匹配或不匹配。
-
如果每個給定字串的最後一個字元匹配,那麼我們應該遞迴呼叫其餘的字串。因此,我們將兩個字串的長度都減少
1並在其上加一以計算字串的長度。 -
但是,如果字元不匹配,則對第一個字串進行遞迴呼叫,將其長度遞減
1,然後對第二個字串進行遞迴呼叫以將其長度遞減1。 -
兩次呼叫之間的最大長度作為我們的結果。
程式碼示例:
def LCS(s1, s2, n, m):
if n == 0 or m == 0:
return 0
if s1[n - 1] == s2[m - 1]:
return 1 + lcs(s1, s2, n - 1, m - 1)
else:
return max(lcs(s1, s2, n, m - 1), lcs(s1, s2, n - 1, m))
s1 = "pokemonGo"
s2 = "watchPokemon"
n = len(s1)
m = len(s2)
res = lcs(s1, s2, n, m)
print("Length of the longest common substring is:", res)
輸出:
Length of the longest common substring is: 7
上述解決方案的時間複雜度為 O(3^(m+n)),空間複雜度為 O(m+n)。
在 Python 中使用動態程式設計查詢最長的公共子字串
動態規劃的基本思想是找到兩個字串的所有子字串的長度,並將它們各自的長度儲存在一個表中。由於使用遞迴,可能會出現堆疊溢位錯誤,因為對於大輸入,遞迴堆疊將不斷增加。
我們引入了動態規劃的概念,我們在其中形成了一個表格,並將繼續儲存各個子字串的結果。我們在遞迴中使用的相同演算法也用於一些更改。
現在,我們將討論在 Python 中查詢最長公共子字串的步驟。
-
首先,初始化表格的第一列和第一行。正如我們在遞迴的基本條件中所見,這些單元格將使用值
0進行初始化。 -
我們使用迴圈而不是遞迴呼叫我們的邏輯。
-
在迴圈內部,如果兩個字串的最後一個字元匹配,我們將特定單元格的長度增加
1。 -
否則,我們將最大長度儲存到特定單元格中的相鄰行和列。
-
最後,我們的結果將儲存在表格的最後一個位置;因此,我們返回
dp[m][n]。
程式碼示例:
def LCS(X, Y, m, n):
dp = [[0 for x in range(m + 1)] for y in range(n + 1)]
for i in range(m + 1):
for j in range(n + 1):
if X[i - 1] == Y[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[m][n]
s1 = "playbatball"
s2 = "batballwicket"
n = len(s1)
m = len(s2)
res = lcs(s1, s2, n, m)
print("Length of the longest common substring is:", res)
輸出:
Length of the longest common substring is: 7
由於我們的解決方案中只有兩個迴圈,因此上述解決方案的時間複雜度將是 O(m*n)。我們通過形成一個表來儲存結果來使用額外的空間。
上述解決方案的空間複雜度為 O(m*n)。
まとめ
我們已經學習了三種不同的方法來查詢兩個給定字串之間的最長公共子字串。第一種方法是一種簡單的方法,使用三個迴圈並查詢給定字串的所有子字串,並檢查所有子字串中最長的。
第二種方法使用遞迴,而第三種方法使用動態程式設計來查詢 Python 中最長的公共子字串。第三種方法將是本文討論的解決問題的所有解決方案中最快的方法,應該是首選方法。