繪製 Pandas 中的 Series
- Pandas 中的各種圖
- 從 Pandas 系列中繪製條形圖
- 繪製 Pandas 系列的線圖
- 繪製 Pandas 系列的箱線圖
- 繪製 Pandas 系列的直方圖 Bin 圖
- 繪製 Pandas 系列的自相關圖
本文探討了使用 Pandas 在 DataFrame 上繪製系列的概念。
無論你是在探索資料集以磨練自己的技能,還是旨在為公司績效分析做出良好的演示,視覺化都起著重要作用。
Python 通過其帶有 .plot() 函式的 Pandas 庫提供了各種選項,以前所未有的形式將我們的資料轉換為可呈現的形式。
即使是業餘 Python 開發人員在瞭解了步驟並遵循正確的程式以產生有價值的見解後,也很容易知道如何使用該庫。
但是,要做到這一點,我們首先需要了解庫的功能以及它如何幫助分析師為公司提供價值。
Pandas 中的各種圖
讓我們通過了解當前存在多少不同的圖來開始本教程。
line- 線圖(這是預設圖)bar- 平行於 Y 軸(垂直)的條形圖barh- 平行於 X 軸的條形圖(水平)hist- 直方圖box- 箱線圖kde- 核密度估計圖density- 與kde相同area- 面積圖pie- 餅圖
Pandas 使用 plot() 方法進行視覺化。此外,pyplot 可以使用 Matplotlib 庫用於圖示。
本教程涵蓋了重要的繪圖型別以及如何有效地使用它們。
從 Pandas 系列中繪製條形圖
顧名思義,當資料為系列形式時,系列圖很重要,並且變數之間應該存在相關性。如果沒有相關性,我們就不會進行視覺化和比較。
下面是一個基於以字典形式給出的虛擬資料繪製基本條形圖的示例。我們可以使用基於真實資料的 CSV 檔案,也可以使用自定義建立的虛擬資料來探索開發和研究的各種選項。
import pandas as pd
import matplotlib.pyplot as plt
s = pd.Series(
{
16976: 2,
1: 39,
2: 49,
3: 187,
4: 159,
5: 158,
16947: 14,
16977: 1,
16948: 7,
16978: 1,
16980: 1,
},
name="article_id",
)
print(s)
# Name: article_id, dtype: int64
s.plot.bar()
plt.show()
上面的程式碼給出了這個輸出。
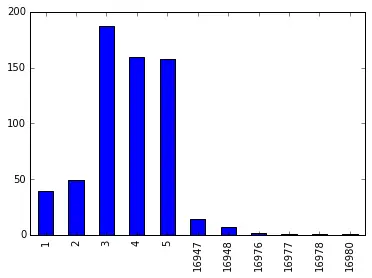
正如我們所看到的,顯示了一個條形圖以幫助進行比較和分析。
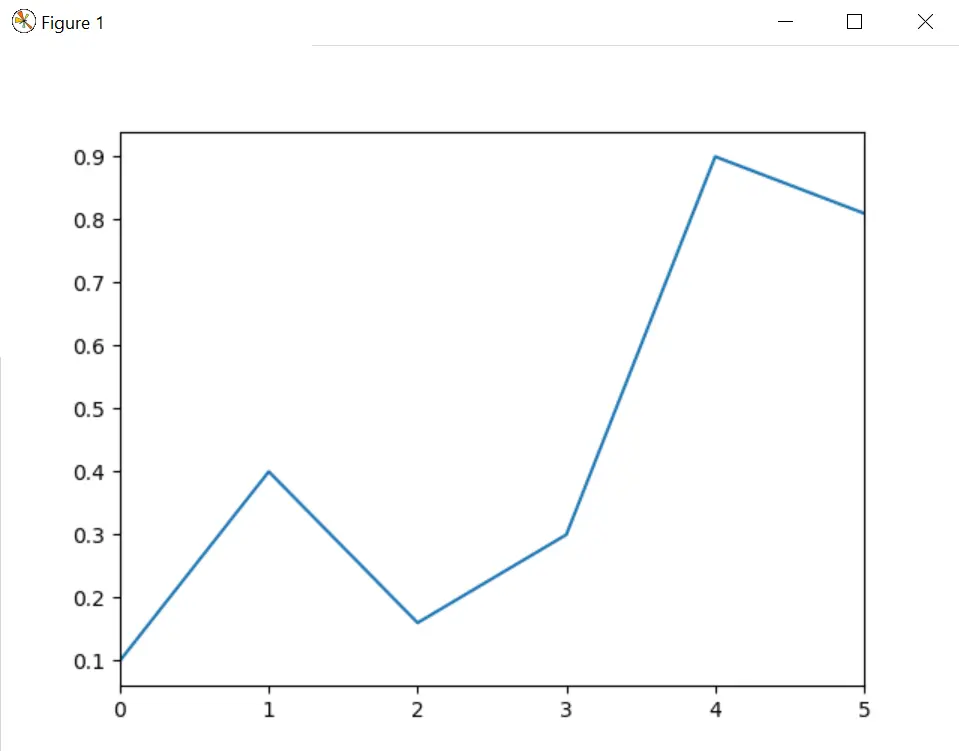
繪製 Pandas 系列的線圖
讓我們再考慮一個例子,我們的目的是根據給定的虛擬資料繪製折線圖。在這裡,我們不應該新增額外的元素和 plot()。
# using Series.plot() method
s = pd.Series([0.1, 0.4, 0.16, 0.3, 0.9, 0.81])
s.plot()
plt.show()
上面的程式碼給出了這個輸出。
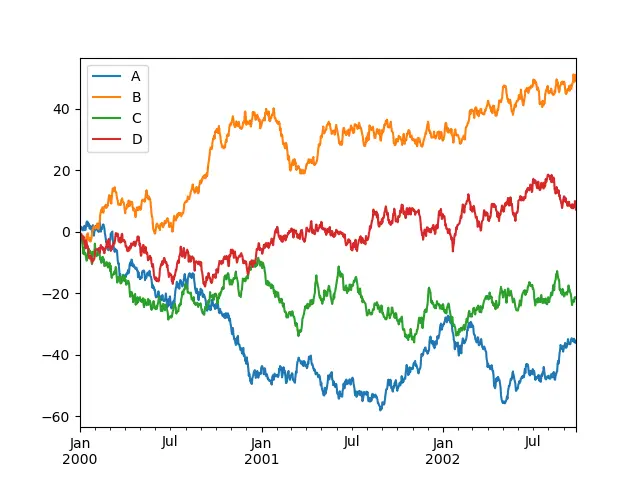
也可以繪製在 Y 軸上包含多個變數的圖表,如下所示。在單個圖中包含多個變數使得比較屬於同一類別的元素更具說明性和可行性。
例如,如果建立了學生在特定考試中的分數圖,它將幫助教授分析每個學生在特定時間間隔內的表現。
import numpy as np
ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))
df = df.cumsum()
plt.figure()
df.plot()
plt.show()
繪製 Pandas 系列的箱線圖
plot() 方法允許除預設線圖以外的其他繪圖樣式。我們可以提供 kind 引數和 plot 函式。
我們可以通過呼叫函式 series.plot.box() 繪製箱線圖來說明每列內的值分佈。箱線圖告訴我們很多關於資料的資訊,例如中位數。
我們還可以通過檢視箱線圖找出第一個、第二個和第三個四分位數。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"])
df.plot.box()
plt.show()
此外,使用 color 關鍵字傳遞其他型別的引數將立即分配給 matplotlib,用於所有 boxes、whiskers、medians 和 caps 著色。
我們只需寫一行就可以獲取下面給出的這個資訊圖表。
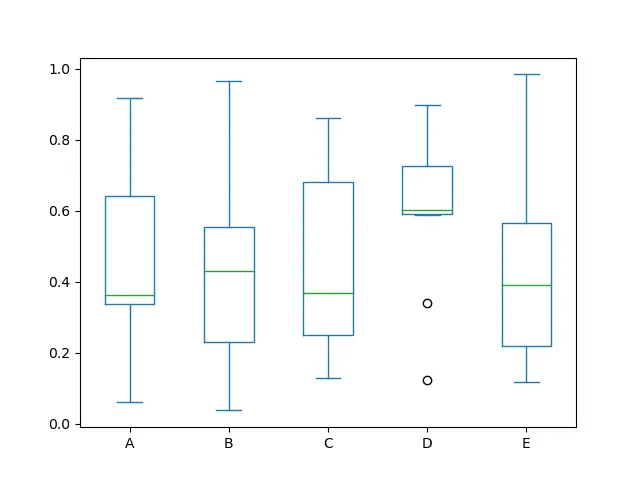
return_type 關鍵字來控制返回型別。繪製 Pandas 系列的直方圖 Bin 圖
接下來,我們將學習如何繪製六邊形 bin 圖和自相關圖。
直方圖 Bin 圖是使用 dataframe.plot.hexbin() 語法建立的。如果資料太密集而無法清楚地繪製每個點,這些是散點圖的良好替代品。
在這裡,一個非常重要的關鍵字是 gridsize,因為它控制沿水平方向的六邊形的數量。更多的網格將傾向於更小和更大的箱。
以下是基於隨機資料的以下程式碼片段。
df = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
df["b"] = df["b"] + np.arange(1000)
df["z"] = np.random.uniform(0, 3, 1000)
df.plot.hexbin(x="a", y="b", C="z", reduce_C_function=np.max, gridsize=25)
plt.show()
上面的程式碼給出了這個輸出。
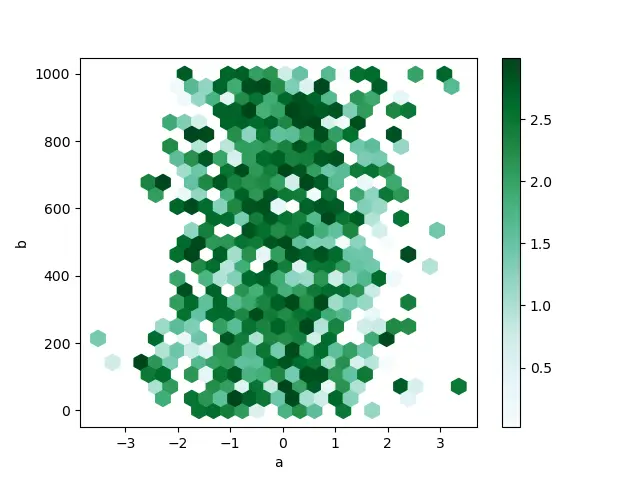
有關六邊形 bin 圖的更多資訊,請導航到 Pandas 官方文件中的 hexbin 方法。
繪製 Pandas 系列的自相關圖
我們以最複雜的繪圖型別結束本教程:自相關圖。該圖通常用於分析基於神經網路的機器學習模型。
它用於描述時間序列中的元素是否正相關、負相關或不相互依賴。我們可以在 Y 軸上找出 自相關 函式 ACF 的值,範圍從 -1 到 1
它有助於糾正時間序列中的隨機性。我們通過計算不同時間滯後的自相關來獲得資料。
平行於 X 軸的線對應於大約 95% 到 99% 的置信帶。虛線是 99% 置信帶。
讓我們看看如何建立這個圖。
from pandas.plotting import autocorrelation_plot
plt.figure()
spacing = np.linspace(-9 * np.pi, 9 * np.pi, num=1000)
data = pd.Series(0.7 * np.random.rand(1000) + 0.3 * np.sin(spacing))
autocorrelation_plot(data)
plt.show()
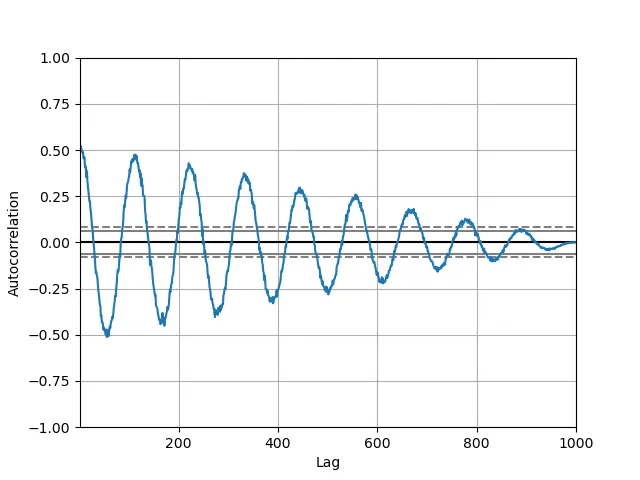
如果時間序列不是基於真實資料,那麼這種自相關對於所有時滯差異都在零附近,如果時間序列基於真實資料,那麼自相關必須是非零的。必須有一個或多個自相關。
