計算 Pandas 的百分比變化
Fariba Laiq
2024年2月15日

pct_change() 是 Pandas 中的一個函式,預設情況下計算前一行元素之間的百分比變化。在時間序列資料的情況下,這個函式被頻繁使用。
此函式的輸出是一個 DataFrame,其中包含上一行的百分比變化值。當我們呼叫這個函式時,我們可以指定其他行作為引數進行比較。
它適用於以下公式。
$$
Pct \space Change = {(Current-Previous) \over Previous}*100
$$
使用 pct_change() 計算 Pandas 的百分比變化
此方法接受四個可選引數,如下所示。
periods- 具有預設值1。它指定要移動的期間以計算百分比變化。fill_method- 指定在計算百分比變化之前如何處理 NA。limit- 指定在停止之前要填充的連續 NA 的數量。freq- 從時間序列 API 中使用的增量(例如'M'或BDay())。
以下是計算兩行之間百分比變化的簡單程式碼。我們將使用 DataFrame 物件呼叫 pct_change() 方法,而不傳遞任何引數。
# Python 3.x
import pandas as pd
df = pd.DataFrame([[2, 4, 6], [1, 2, 3], [5, 7, 9]])
print(df.pct_change())
輸出:

在計算 Pandas 的百分比變化之前填充缺失值
例如,我們在 DataFrame 中有 missing 或 None 值。在計算百分比變化時,缺失的資料將由上一行中的相應值填充。
這裡,ffill 表示前向填充。
# Python 3.x
import pandas as pd
df = pd.DataFrame([[2, 4, 6], [1, None, 3], [None, 7, 9]])
print(df.pct_change(fill_method="ffill"))

計算 Pandas 中 Multi-Index DataFrame 的百分比變化
我們還可以計算多索引 DataFrame 的百分比變化。我們可以使用 groupby() 方法根據某些標準將資料分成組,然後應用 pct_change()。
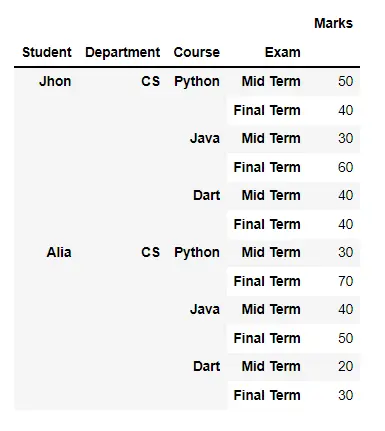
# Python 3.x
df = pd.DataFrame(
index=pd.MultiIndex.from_product(
[
["Jhon", "Alia"],
["CS"],
["Python", "Java", "Dart"],
["Mid Term", "Final Term"],
],
names=["Student", "Department", "Course", "Exam"],
),
data={"Marks": [50, 40, 30, 60, 40, 40, 30, 70, 40, 50, 20, 30]},
)
print(df)
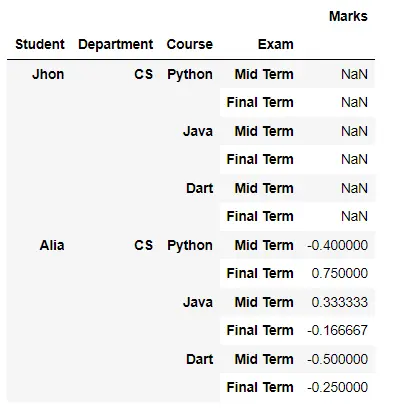
print(df.groupby(level=[1, 2, 3]).pct_change())
輸出:
作者: Fariba Laiq

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn