Pandas 中的 Groupby 索引列

本教程介紹 Python Pandas 中的 groupby 如何對資料進行分類並將函式應用於類別。使用 groupby() 函式通過示例對 Pandas 中的多個索引列進行分組。
在 Python Pandas 中使用 groupby() 函式按索引列分組
在這篇文章中,Pandas DataFrame data.groupby() 函式根據特定標準將資料分組。Pandas 物件可以沿任意軸分為任意數量的組。
標籤到組名的對映是分組的抽象定義。groupby 操作拆分物件、應用函式並組合結果。
這對於對大量資料進行分組和執行操作很有用。Pandas groupby 預設行為將 groupby 列轉換為索引,並將它們從 DataFrame 的列列表中刪除。
語法:
DataFrame.groupby(
by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True
)
引數:
by |
對映、函式、字串或可迭代物件 |
axis |
整數,預設值 0 |
level |
對於多索引軸,按特定級別或級別(分層)分組。 |
as_index |
作為聚合輸出的索引,返回一個帶有組標籤的物件。這僅適用於 DataFrame 輸入。當 index=False 時,輸出以 SQL 樣式分組。 |
sort |
應該對組中的鍵進行排序。將其關閉以提高效能。應該注意的是,每組內的觀察順序不受此影響。Groupby 維護每個組內的行順序。 |
group_keys |
呼叫 apply 時將組鍵新增到索引以識別碎片擠壓:如果可能,減少返回型別的維數;否則,返回一致的型別。 |
取一個包含兩列的 DataFrame:date 和 item sell。Groupby 日期和專案銷售並獲取使用者的逐項計數。
首先,我們需要匯入必要的庫 pandas 和 numpy,建立三個列 ct、date 和 item_sell 並將一組值傳遞給這些列。
import pandas as pd
import numpy as np
data = pd.DataFrame()
data["date"] = ["a", "a", "a", "b"]
data["item_sell"] = ["z", "z", "a", "a"]
data["ct"] = 1
print(data)
輸出:
date item_sell ct
0 a z 1
1 a z 1
2 a a 1
3 b a 1
使用 date 和 item_sell 列進行分組。
import pandas as pd
import numpy as np
data = pd.DataFrame()
data["date"] = ["a", "a", "a", "b"]
data["item_sell"] = ["z", "z", "a", "a"]
data["ct"] = 1
output = pd.pivot_table(data, values="ct", index=["date", "item_sell"], aggfunc=np.sum)
print(output)
輸出:
ct
date item_sell
a a 1
z 2
b a 1
groupby() by 引數現在可以引用列名稱或索引級別名稱。
import pandas as pd
import numpy as np
arrays = [
["rar", "raz", "bal", "bac", "foa", "foa", "qus", "qus"],
["six", "seven", "six", "seven", "six", "seven", "six", "seven"],
]
index = pd.MultiIndex.from_arrays(arrays, names=["first", "second"])
data = pd.DataFrame({"C": [1, 1, 1, 1, 2, 2, 3, 3], "D": np.arange(8)}, index=index)
print(data)
輸出:
C D
first second
rar six 1 0
raz seven 1 1
bal six 1 2
bac seven 1 3
foa six 2 4
seven 2 5
qus six 3 6
seven 3 7
按 second 和 C 分組,然後使用 sum 函式計算總和。
import pandas as pd
import numpy as np
arrays = [
["rar", "raz", "bal", "bac", "foa", "foa", "qus", "qus"],
["six", "seven", "six", "seven", "six", "seven", "six", "seven"],
]
index = pd.MultiIndex.from_arrays(arrays, names=["first", "second"])
data = pd.DataFrame({"C": [1, 1, 1, 1, 2, 2, 3, 3], "D": np.arange(8)}, index=index)
output = data.groupby(["second", "C"]).sum()
print(output)
輸出:

在 Python Pandas 中對 CSV 檔案資料使用 groupby() 函式
現在對 CSV 檔案使用 groupby() 函式。要下載程式碼中使用的 CSV 檔案,請單擊此處([學生在考試中的表現 | Kaggle])。
使用的 CSV 檔案是關於學生表現的。要根據 gender 對資料進行分組,請使用 groupby() 函式。
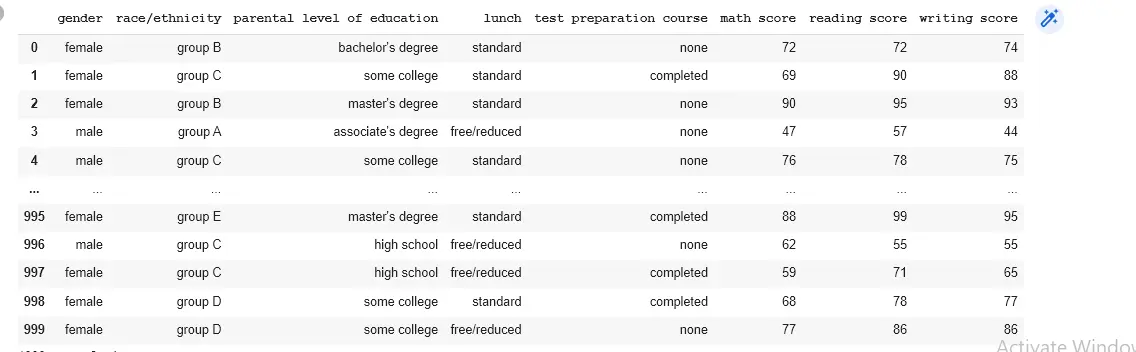
Python Pandas 庫的 read_csv 函式用於從驅動器中讀取檔案。將檔案儲存在資料變數中。
import pandas as pd
data = pd.read_csv("/content/drive/MyDrive/CSV/StudentsPerformance.csv")
print(data)
輸出:
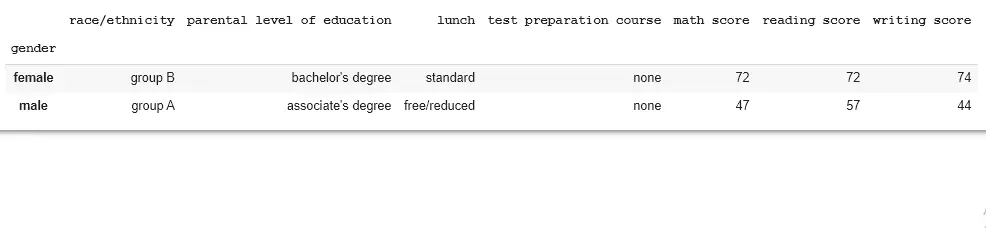
應用 groupby() 函式。
import pandas as pd
data = pd.read_csv("StudentsPerformance.csv")
std = data.groupby("gender")
print(std.first())
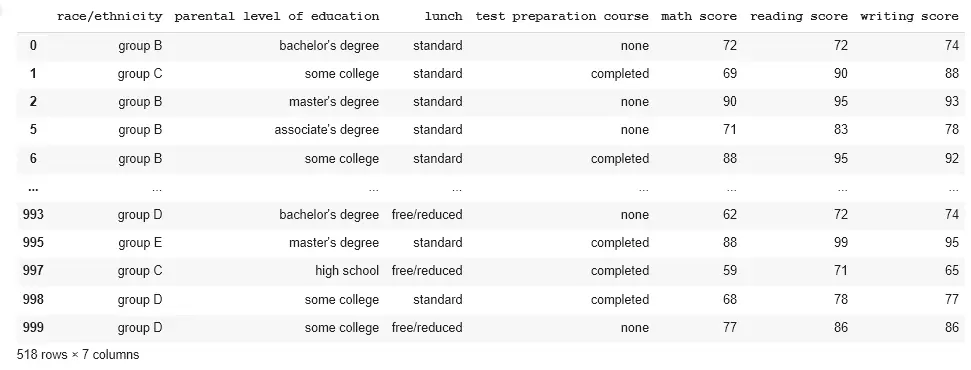
讓我們列印任何組中的值。為此,請使用團隊的名稱。
get_group 函式用於查詢任何組中的條目。找出 female 組中包含的值。
import pandas as pd
data = pd.read_csv("StudentsPerformance.csv")
std = data.groupby("gender")
print(std.get_group("female"))
輸出:
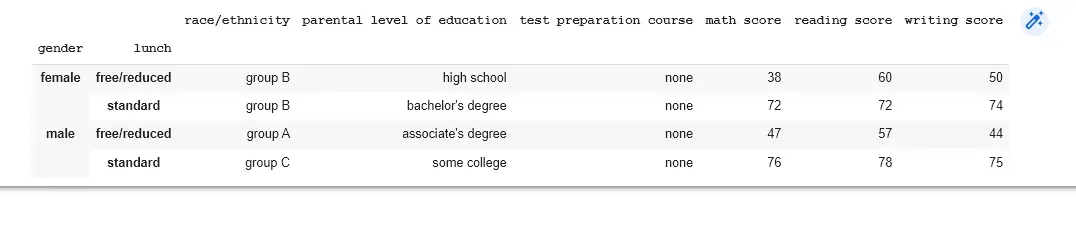
使用 groupby() 函式建立多個類別組。要拆分,請使用多個列。
import pandas as pd
data = pd.read_csv("StudentsPerformance.csv")
std_per = data.groupby(["gender", "lunch"])
print(std_per.first())
輸出:
Groupby() 是一個具有多種變體的通用函式。它使得根據某些標準拆分 DataFrame 變得非常簡單和高效。