Pandas 中的 GroupBy 和聚合多列資料
Fariba Laiq
2024年2月15日

Pandas 庫是 Python 中一個強大的資料分析庫。我們可以在 Python 中使用 Pandas 對資料框執行許多不同型別的操作。
groupby() 是一種根據特定標準將資料分成多個組的方法。之後,我們可以對分組的資料進行某些操作。
在 Pandas Python 中的多列上應用 groupby() 和 aggregate() 函式
有時我們需要對來自多個列的資料進行分組並應用一些 aggregate() 方法。aggregate() 方法是那些將多行的值組合並返回單個值的方法,例如 count()、size()、mean()、sum()、mean() 等
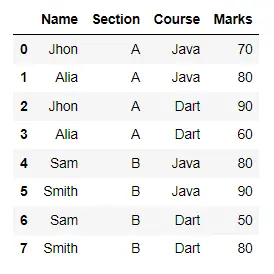
在以下程式碼中,我們的學生資料包含某些列的冗餘值。如果你想根據學生的姓名和部門對資料進行分組以獲得他們的總分,我們將根據名稱和部門對資料進行分組,然後使用 aggregate() 方法計算總分。
我們已經儲存了返回的結果並顯示了它。
示例程式碼:
# Python 3.x
import pandas as pd
student = {
"Name": ["Jhon", "Alia", "Jhon", "Alia", "Sam", "Smith", "Sam", "Smith"],
"Section": ["A", "A", "A", "A", "B", "B", "B", "B"],
"Course": ["Java", "Java", "Dart", "Dart", "Java", "Java", "Dart", "Dart"],
"Marks": [70, 80, 90, 60, 80, 90, 50, 80],
}
df = pd.DataFrame(student)
display(df)
result = df.groupby(["Name", "Section"]).aggregate("sum")
display(result)
輸出:
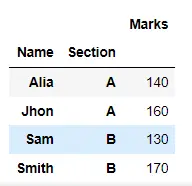
我們還可以一次執行多個聚合操作。我們會將操作名稱列表傳遞給 aggregate() 方法。
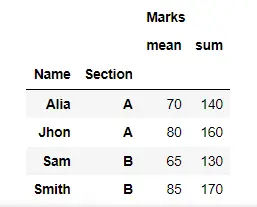
在這裡,我們通過傳遞操作名稱列表,使用 aggregate() 方法一次計算學生的平均分和總分。
示例程式碼:
# Python 3.x
import pandas as pd
student = {
"Name": ["Jhon", "Alia", "Jhon", "Alia", "Sam", "Smith", "Sam", "Smith"],
"Section": ["A", "A", "A", "A", "B", "B", "B", "B"],
"Course": ["Java", "Java", "Dart", "Dart", "Java", "Java", "Dart", "Dart"],
"Marks": [70, 80, 90, 60, 80, 90, 50, 80],
}
df = pd.DataFrame(student)
display(df)
result = df.groupby(["Name", "Section"]).aggregate(["mean", "sum"])
display(result)
輸出:
作者: Fariba Laiq

I am Fariba Laiq from Pakistan. An android app developer, technical content writer, and coding instructor. Writing has always been one of my passions. I love to learn, implement and convey my knowledge to others.
LinkedIn