將函式應用於 Pandas DataFrame 中的每一行
-
Pandas
apply()函式的基本語法 -
將
lambda函式應用於 PandasDataFrame中的每一行 -
將
NumPy函式應用於 PandasDataFrame的每一行 -
使用引數將使用者定義的函式應用於 Pandas
DataFrame的每一行 -
將使用者定義的函式應用於每行 Pandas
DataFrame無引數
Pandas 是一個 Python 庫,它提供了大量的類和函式,用於以更簡單的方式執行資料分析和操作任務。我們以行和列的形式操作 Pandas DataFrame 中的資料。因此,大多數時候,我們需要對每一行或每一列應用適當的函式,以獲得想要的結果。
本文將探討如何使用 Pandas 將函式應用於 Pandas DataFrame 中的每一行。此外,我們將演示如何將各種函式(例如 lambda 函式、使用者定義函式和 NumPy 函式)應用於 Pandas DataFrame 中的每一行。
Pandas apply() 函式的基本語法
以下基本語法用於應用 Pandas apply() 函式:
DataFrame.apply(function, axis, args=())
參見上面的語法中,函式被應用到每一行。axis 是函式在 DataFrame 中應用的引數。預設情況下,axis 值為 0。axis=1 的值,如果函式適用於每一行。args 表示傳遞給函式的元組或引數列表。
使用 pandas apply() 函式,我們可以輕鬆地將不同的函式應用於 DataFrame 中的每一行。以下列出的方法可幫助我們實現這一目標:
將 lambda 函式應用於 Pandas DataFrame 中的每一行
為了將 lambda 函式應用於 DataFrame 中的每一行,我們使用 lambda 函式作為 DataFrame 中的第一個引數,並將 axis=1 作為 DataFrame 中的第二個引數傳遞。apply() 使用上面建立的 DataFrame。
要了解如何將 lambda 函式應用於 DataFrame 中的每一行,請嘗試以下示例:
示例程式碼:
import pandas as pd
import numpy as np
from IPython.display import display
# List of Tuples data
data = [
(1, 34, 23),
(11, 31, 11),
(22, 16, 21),
(33, 32, 22),
(44, 33, 27),
(55, 35, 11),
]
# Create a DataFrame object
dataframe = pd.DataFrame(data, columns=list("ABC"))
print("Original Dataframe before applying lambda function: ", sep="\n")
display(dataframe)
# Apply a lambda function to each row by adding 10
new_dataframe = dataframe.apply(lambda x: x + 10, axis=1)
print("Modified New Dataframe by applying lambda function on each row:")
display(new_dataframe)
輸出:
Original Dataframe before applying lambda function:
A B C
0 1 34 23
1 11 31 11
2 22 16 21
3 33 32 22
4 44 33 27
5 55 35 11
Modified Dataframe by applying lambda function on each row:
A B C
0 11 44 33
1 21 41 21
2 32 26 31
3 43 42 32
4 54 43 37
5 65 45 21

將 NumPy 函式應用於 Pandas DataFrame 的每一行
我們還可以使用作為引數傳遞給 dataframe.apply() 的 NumPy 函式。在以下示例中,我們將 NumPy 函式應用於每一行並計算每個值的平方根。
示例程式碼:
import pandas as pd
import numpy as np
from IPython.display import display
def main():
# List of Tuples
data = [
(2, 3, 4),
(3, 5, 10),
(44, 16, 2),
(55, 32, 12),
(60, 33, 27),
(77, 35, 11),
]
# Create a DataFrame object
dataframe = pd.DataFrame(data, columns=list("ABC"))
print("Original Dataframe", sep="\n")
display(dataframe)
# Apply a numpy function to every row by taking square root of each value
new_dataframe = dataframe.apply(np.sqrt, axis=1)
print("Modified Dataframe by applying numpy function on each row:", sep="\n")
display(new_dataframe)
if __name__ == "__main__":
main()
輸出:
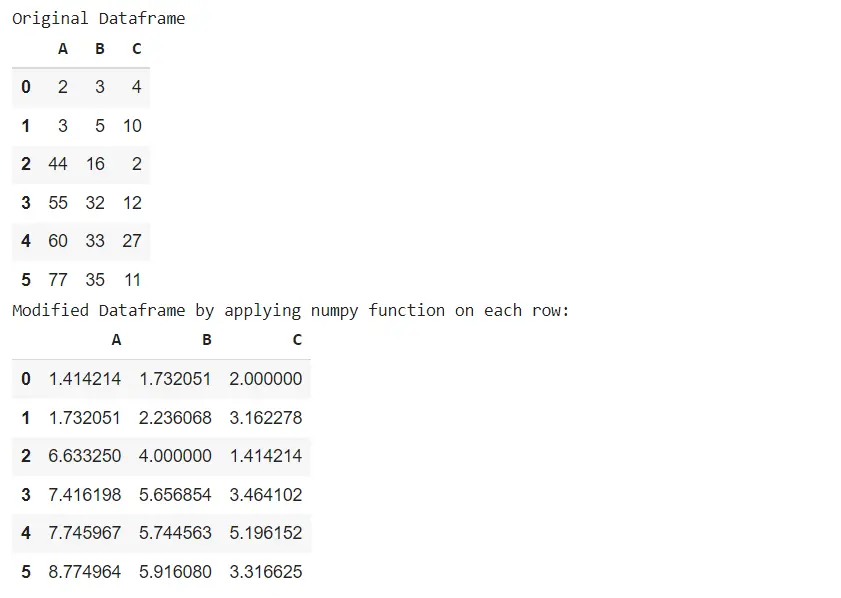
Original Dataframe
A B C
0 2 3 4
1 3 5 10
2 44 16 2
3 55 32 12
4 60 33 27
5 77 35 11
Modified Dataframe by applying numpy function on each row:
A B C
0 1.414214 1.732051 2.000000
1 1.732051 2.236068 3.162278
2 6.633250 4.000000 1.414214
3 7.416198 5.656854 3.464102
4 7.745967 5.744563 5.196152
5 8.774964 5.916080 3.316625
使用引數將使用者定義的函式應用於 Pandas DataFrame 的每一行
我們還可以將 user defined 函式作為帶有一些引數的 dataframe.apply 中的引數傳遞。在下面的例子中,我們傳遞了一個使用者定義的函式,引數為 args=[2]。每個行值系列乘以 2。
請參閱以下示例:
示例程式碼:
import pandas as pd
import numpy as np
from IPython.display import display
def multiplyData(x, y):
return x * y
def main():
# List of Tuples
data = [
(2, 3, 4),
(3, 5, 10),
(44, 16, 2),
(55, 32, 12),
(60, 33, 27),
(77, 35, 11),
]
# Create a DataFrame object
dataframe = pd.DataFrame(data, columns=list("ABC"))
print("Original Dataframe", sep="\n")
display(dataframe)
# Apply a user defined function with arguments to each row of Pandas dataframe
new_dataframe = dataframe.apply(multiplyData, axis=1, args=[2])
print(
"Modified Dataframe by applying user defined function on each row of pandas dataframe:",
sep="\n",
)
display(new_dataframe)
if __name__ == "__main__":
main()
輸出:
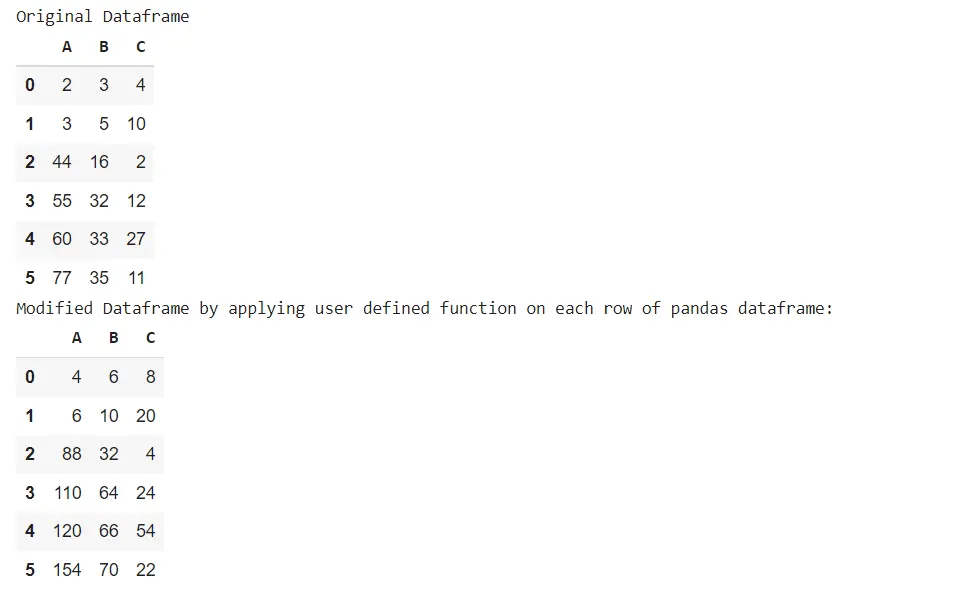
Original Dataframe
A B C
0 2 3 4
1 3 5 10
2 44 16 2
3 55 32 12
4 60 33 27
5 77 35 11
Modified Dataframe by applying user defined function on each row of pandas dataframe:
A B C
0 4 6 8
1 6 10 20
2 88 32 4
3 110 64 24
4 120 66 54
5 154 70 22
將使用者定義的函式應用於每行 Pandas DataFrame 無引數
我們還可以在沒有任何引數的情況下將使用者定義的函式應用於每一行。請參閱以下示例:
示例程式碼:
import pandas as pd
import numpy as np
from IPython.display import display
def userDefined(x):
return x * 4
def main():
# List of Tuples
data = [
(2, 3, 4),
(3, 5, 10),
(44, 16, 2),
(55, 32, 12),
(60, 33, 27),
(77, 35, 11),
]
# Create a DataFrame object
dataframe = pd.DataFrame(data, columns=list("ABC"))
print("Original Dataframe", sep="\n")
display(dataframe)
# Apply a user defined function without arguments to each row of Pandas dataframe
new_dataframe = dataframe.apply(userDefined, axis=1)
print(
"Modified Dataframe by applying user defined function on each row of pandas dataframe:",
sep="\n",
)
display(new_dataframe)
if __name__ == "__main__":
main()
輸出:
Original Dataframe
A B C
0 2 3 4
1 3 5 10
2 44 16 2
3 55 32 12
4 60 33 27
5 77 35 11
Modified Dataframe by applying user defined function on each row of pandas dataframe:
A B C
0 8 12 16
1 12 20 40
2 176 64 8
3 220 128 48
4 240 132 108
5 308 140 44
