在 PostgreSQL 中選擇字串是否包含子串匹配
-
在 PostgreSQL 中如果字串包含子字串匹配,則使用
like運算子SELECT -
在 PostgreSQL 中如果字串包含子字串匹配,則使用
position()函式SELECT -
在 PostgreSQL 中如果字串包含子字串匹配,則使用
similar to正規表示式來SELECT -
在 PostgreSQL 中如果字串包含子字串匹配,則使用
substring()函式SELECT -
在 PostgreSQL 中如果字串包含子字串匹配,則使用
Posix正則運算子來SELECT

今天,我們將學習如何在 PostgreSQL 字串中查詢一個值,並在它匹配特定條件時選擇它。
假設你有一個字串 carabc,並想檢視它是否包含值 car。因此,你將嘗試使用一個函式來告訴你字串中是否存在這樣的子字串。
PostgreSQL 提供了三種方法:like、similar to 和 Posix 運算子。我們將詳細討論這些。
在 PostgreSQL 中如果字串包含子字串匹配,則使用 like 運算子 SELECT
如果字串包含特定的子字串,like 表示式將返回 True;否則,錯誤。首先,我們建立一個表並在其中插入一些值:
create table strings(
str TEXT PRIMARY KEY
);
insert into strings values ('abcd'), ('abgh'), ('carabc');
現在,讓我們從該表中選擇 abc 值。
select * from strings where str like 'abc';
當我們執行它時,什麼也沒有發生。顯示一個空表。
為什麼它沒有從表中返回 abcd 和 carabc?看看下面的語句並嘗試看看會發生什麼:
select * from strings where str like 'abcd';
輸出:
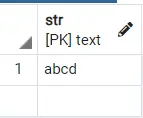
因此,現在你看到呼叫 like 往往會返回與我們嘗試匹配的字串完全相同的結果。
要將其與子字串匹配,你需要在嘗試匹配的子字串中新增一個%。
以下提供了一個更好的示例來說明如何做到這一點:
select * from strings where str like '%abc%';
輸出:
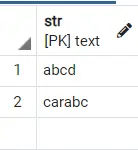
%x 告訴查詢我們需要在字串中的一些其他值位於此 x 後面之後找到 x。如果我們想找到 carabc,我們會說%abc,它會返回 carabc,因為 car 附加在 abc 之前。
但是如果我們想返回 abcd,我們將使用 x%,因為 d 附加在 x 之後。自己嘗試一下,看看結果以獲得更好的理解!
因為我們想檢查一個字串是否包含可能位於左側、右側或中間的 abc,所以我們使用%abc%返回所有此類字串。
like 運算子也可以寫為~~,如果 not like,則使用!~~。
另一個表示式被稱為 Ilike 有助於匹配字串而不區分大小寫。這意味著如果我們使用以下語句:
select * from strings where str Ilike '%Abc%';
即使 abc 不等於 Abc,它也會返回先前的結果,因為 a 在子字串中大寫。
與 like 運算子一樣,你可以將 Ilike 寫為~~*,將 not Ilike 寫為!~~*。
假設你要執行查詢來檢查表中與特定字串匹配的記錄。如果要將 abcde 與表中的記錄進行比較並返回匹配的行,可以使用:
select * from strings where 'abcd' like '%' || str || '%'
這會將 str 列中的行附加到 %_str_% 的語法中,然後我們可以比較其中的每個值並檢視哪些匹配。
輸出:
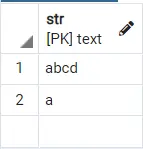
要將子字串與諸如 escape、%或反斜槓/、\之類的流氓字元匹配,你可以使用,
select * from strings where 'abcd' like '%/abc'
這將不返回任何內容,因為函式無法消除值%。這將我們帶到下一點,使用 position 函式。
在 PostgreSQL 中如果字串包含子字串匹配,則使用 position() 函式 SELECT
position() 函式是檢查字串中是否存在子字串的更好選擇。這是在 PostgreSQL 文件中的字串操作下定義的。
它返回在主字串中找到的子字串的索引。因此,如果我們要在 carabc 中找到 car,它將返回 1。
這樣,我們可以通過檢查返回索引的值來檢視字串中是否存在任何子字串。如果大於 0,則子串存在;否則,它不會。
select * from strings where position(str in 'abcde') > 0
上面的語句將返回兩個值,a 和 abcd,因為它們都存在於 abcde 中。你可以根據需要進行操作。
此外,如果你的子字串中有任何其他字元,例如 %,它會在檢查中跳過該字元並返回準確的結果,使其比 like 表示式好得多。
select * from strings where position(str in '% abcde') > 0
執行上述將給出相同的結果。
position 表示式的可能替代品可以是 strpos,它同樣有效。
在 PostgreSQL 中如果字串包含子字串匹配,則使用 similar to 正規表示式來 SELECT
like 和 similar to 之間的唯一區別是後者是在各種其他 DMBS 中使用的標準 SQL 定義。
select * from strings where position(str in 'abcde') > 0
這將返回與 like 表示式相同的結果。
要使用替代匹配,你可以使用:
select * from strings where str similar to '%(abc|a)%'
這將返回匹配 abc 或 a 的所有字串。當我們執行這個查詢時,我們會返回表中的所有字串,因為每個字串都包含一個 a。
如果你想禁用匹配子字串中的任何元字元,你可以使用反斜槓 \ 來禁用我們傾向於在字串中稱為流氓字元的內容。
在 PostgreSQL 中如果字串包含子字串匹配,則使用 substring() 函式 SELECT
可以對 substring() 函式進行另一種操作,如下所示:
select * from strings where str ~~ substring(str similar '%abc%' escape '#')
substring() 在我們的例子中返回類似於 abc 或包含 abc 的字串。然後,我們使用 ~~ 運算子(like 的縮寫)將返回的結果與 str 匹配,如果匹配,我們從表中選擇結果。
這個簡單的函式甚至有助於將字串分成單獨的部分,可以在提供的語法中看到:
substring(string similar pattern escape escape-character)
or
substring(string from a pattern for escape-character)
or
substring(string, pattern, escape-character)
escape-character 傾向於將要匹配的字串分成不同的部分,如果它在不同點包含 escape-character。
因此,如果我們執行該語句:
select * from strings where str ~~ substring(str similar '#"abcd#"%' escape '#')
'#"abcd#"%' 將被分成 abcd,用兩個 # 字元括起來。因此,我們也可以找到匹配的字串 abcd。
在 PostgreSQL 中如果字串包含子字串匹配,則使用 Posix 正則運算子來 SELECT
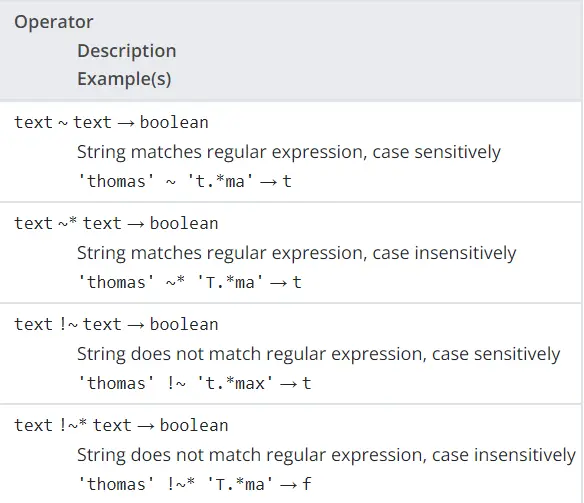
以上內容取自 PostgreSQL 文件中描述的執行相同匹配功能的 Posix 運算子的表。
你可以使用如下語句來檢視字串是否包含子字串:
select * from strings where str ~ 'abc'
這將返回值 carabc 和 abcd。
你甚至可以使用 regexp_match(string, pattern [, flags]),如果沒有找到匹配項,則返回 null。如果找到匹配項,它將返回一個陣列,其中包含與模式匹配的所有子字串。
要理解這一點,請檢視以下查詢:
select regexp_match('abdfabc', 'abd')
輸出:
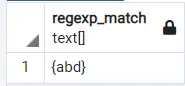
使用另一個查詢,
select regexp_match('abdfabc', 'abf')
輸出:
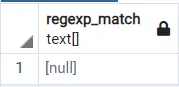
現在,你將看到這個表示式如何找到一個模式並返回它。你可以在函式中使用此表示式,呼叫該函式進行 select 操作,然後返回所有匹配的字串。

Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub