在 PostgreSQL 中將平均值舍入到小數點後 2 位

今天,我們將學習在 PostgreSQL 中將平均值舍入到小數點後 2 位。
在 PostgreSQL 中使用 AVG() 函式獲取集合的平均值
AVG() 函式給出 PostgreSQL 中的平均值。這是一個聚合函式,允許我們計算平均值。
語法:
AVG(Column_Name)
假設我們要計算表 CAT 中具有 ID 和名稱的列的平均值。然後,我們可以這樣做,如下所示。
SELECT AVG(Name) from CAT;
這將返回表 CAT 列內的值的平均值。
讓我們看看如何將獲得的平均值四捨五入到不同的小數位。
使用 ROUND 函式將平均值舍入到 2 個小數位
ROUND 函式在 PostgreSQL 文件的 MATHEMATICAL FUNCTIONS AND OPERATORS 標題下給出。數學函式返回與其引數中提供的相同的資料型別。
ROUND 函式有兩種不同的語法。
語法 1:
ROUND(dp or numeric)
語法 2:
ROUND(v numeric, s int)
第一個查詢型別傾向於四捨五入到最接近的整數,這意味著你不能提供自定義小數位。因此,如果你在 42.4 上呼叫 ROUND 函式,它將返回 42。
如果你在函式中提供小數位引數,則引數中的 DP 代表雙精度。數字型別可以是 2、4 和 8 位元組浮點數或具有可選精度的浮點數。
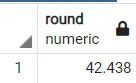
第二個函式還考慮了你可能想要四捨五入的小數位,因此如果你呼叫一個函式將數字 42.4382 四捨五入為 3 位小數,你可以編寫如下查詢:
select ROUND(42.4382, 3)
輸出:
你還可以看到執行以下內容:
select ROUND(42.5)
它將返回 43 作為整數,用 0.5 向上舍入趨向於舍入到最接近整數的上限部分。下限整數為 42,上限部分為 43。
現在,讓我們製作一個表格,看看我們如何執行以下內容。讓我們用兩列 ID 和 CGPA 定義一個表 STUDENT。
CREATE TABLE student (
ID int PRIMARY KEY,
CGPA float8
)
現在讓我們呼叫 INSERT 語句將一些值輸入到這個新建立的表中。
insert into student values (1, 2.3), (2, 4), (3, 4) , (4, 3.76)
假設我們想要獲得此表中列出的所有 CGPA 的 AVERAGE。使用 INTEGER 引數會導致我們得到不準確的答案。
所以我們可以執行一個查詢:
select round(avg(CGPA), 2)
from student
為什麼我們使用 2?因為它是我們所有 CGPA 中最多的小數位數。
我們可以使用這個數字四捨五入得到一個非常準確的答案。但是為什麼會出現錯誤?
輸出:
ERROR: function round(double precision, integer) does not exist
LINE 10: select round(avg(CGPA), 2)
前一個 ROUND 語句允許 DP(雙精度),但後一個查詢語法不允許。
在該函式中,你只能使用小數點前最多 131072 位的數字。之後最多為 16383 位。
因此,float8 不起作用,因此你會遇到語法錯誤。
在 PostgreSQL 中使用 CAST 來消除四捨五入的語法錯誤
在之前的解決方案中,我們遇到了一個問題,即 ROUND 的後一種語法不支援浮點或雙精度型別。因此,要執行查詢,我們可以將 CAST 轉換為數字作為可能的解決方案。
眾所周知,numeric 的小數點後可以有大約 17000 位數字。我們可以繼續有效地使用 CAST。
select round(avg(CGPA)::numeric, 2)
from student
這將返回 3.52,即對 CGPA 集進行四捨五入的確切結果。我們可以用於 CAST 的另一種語法是:
select round(CAST(avg(CGPA) as numeric), 2)
from student
在 PostgreSQL 中使用 TO CHAR 進行更好的十進位制格式和舍入
在 PostgreSQL 中舍入任何數字的另一個方便的解決方法是使用 TO_CHAR 函式。它存在於 PostgreSQL 中的 DATA TYPE FORMATTING FUNCTIONS 分類下。
它有助於將各種資料型別轉換為字串,反之亦然。我們可以使用以下語法轉換為自定義小數位。
to_char ( numeric_type, text ) ? text
to_char(125, '999') ? 125
to_char(125.8::real, '999D9') ? 125.8
to_char(-125.8, '999D99S') ? 125.80-
你可以在上面看到的第二個引數有助於定義我們對數字進行四捨五入並列印其輸出的模板。因此,如果我們想將一個數字四捨五入到特定的小數位,我們可以將模板定義為以下之一。
FM(字首) - 填充模式(抑制前導零和填充空白),FMMonthTH(字尾)- 大寫序數字尾,DDTH,例如12THthe(字尾)- 小寫序數字尾,DDth,例如12thFX(字首)- 固定格式全域性選項(見使用說明),FX Month DD DayTM(字首) - 翻譯模式(使用基於 lc_time 的本地化日期和月份名稱),TMMonthSP(字尾) - 拼寫模式(未實現),DDSP
使用 TO_CHAR 函式,讓我們使用 TO_CHAR 函式對數字 352.45 進行四捨五入。
select to_char(352.45, 'FM999D9')
輸出:
352.5
這意味著這可以正常工作。但是你可能想知道,我們附加到整數的 D 和 FM 是什麼?
D 表示尾隨小數位,並定義查詢將其四捨五入的值的數量。
FM 代表填充模式。它刪除所有空白和前導零。
如果你不把 FM 放在它前面,它會給出這樣的輸出。
輸出:
"[........] 352.5"
因此,在我們的四捨五入結果之前放置 FM 會刪除無效字元。
在 PostgreSQL 中為 ROUND 使用自定義過載函式
另一種對平均值進行四捨五入的方法可能是原始 ROUND 函式不支援的浮點型別,可以是建立一個可以過載它的函式。然後將提供的浮點型別引數 CAST 轉換為數字,以便 ROUND 起作用。
此函式將再次呼叫 ROUND,但 CAST 是傳遞給 numeric 的第一個引數。
例子:
create function ROUND(num float, decim_places int) returns NUMERIC as $f$
select ROUND(num::numeric, decim_places)
$f$ language SQL immutable
然後我們呼叫 ROUND 函式如下。
select ROUND(avg(cgpa), 2) from student
現在,這將在我們的查詢中返回正確的結果,而無需任何 CASTING。
ROUND 過載函式有兩個引數,一個是浮點數,另一個是整數。此函式返回由 SELECT ROUND() 操作正式返回的數值資料型別,該操作將 NUM 引數轉換為數值。
為什麼我們在函式中使用 IMMUTABLE 關鍵字?可以使用 IMMUTABLE、STABLE 或 VOLATILE 關鍵字定義函式。
IMMUTABLE 屬性意味著如果一個函式不斷地被賦予相同的引數,它不會呼叫該函式而是返回恆定的函式值。
如果你檢視 PostgreSQL 文件的 FUNCTION VOLATILITY CATEGORIES 分類,你會注意到 IMMUTABLE 關鍵字的一個很好的示例。
如果你執行上面的查詢,
SELECT Round(3.52, 1)
它返回一次 3.5;然後,如果你再次呼叫該函式,該函式將不會執行該查詢。相反,它返回 3.5 作為其自身,因為引數未更改。
如果在建立函式時未定義此類屬性,則這些函式中的任何一個的預設值為 VOLATILE。
對 PostgreSQL 中建立的 ROUND 函式的修改
可以修改我們上面建立的 ROUND 函式,以使用精度值為我們提供更好看的結果。
假設我們要將 21.56 四捨五入到 0.05 的精度;答案是怎麼出來的?
如果我們沒有定義精度,那麼只有 21.56 的 ROUND 函式將返回 22。但是,在精度為 0.05 的情況下,我們可能需要解決 (+- 0.05) 的值錯誤。
一個很好的方法是將數字除以定義的準確度值,即 0.05,四捨五入我們得到的答案,然後再次乘以 0.05(準確度值)。
因此,如果我們想用更好的估計來四捨五入 21.56,我們可以說:
21.56/0.05 = 431.2
使用值 431.2,我們可以將其四捨五入為 431,然後將其乘以 0.05 得到答案 21.55,完美地四捨五入而沒有錯誤 (+- 0.05)。
如果我們希望答案在小數點後一位以內,我們可以假設誤差為 (+- 0.5),然後執行以下操作:
21.56/0.5 = 43.12
四捨五入將得到 43,乘以 0.5 得到舍入值 21.5。這很好,因為存在估計錯誤,並且 (21.56 ~~ 21.6) 以這種方式不正確。
現在你瞭解了準確性的工作原理,讓我們再次使用 ROUND 定義一個函式以返回正確的值。我們將傳遞兩個引數,一個是我們要四捨五入的數字,另一個是準確度值。
該函式的其餘部分將遵循與上面提供的相同的語法。
create function ROUND(num float, acc float) returns FLOAT as $f$
select ROUND(num/acc)*acc
$f$ language SQL immutable
因此,當你以 0.05 的準確度值執行查詢時,
select ROUND(avg(cgpa), 0.02::float8) from student
輸出:
3.52 (double precision)
為了安全起見,我們使用了 FLOAT8 鑄件;如果我們有另一個具有相同數量引數的函式,我們可能會混淆我們的 PostgreSQL 資料庫。
PostgreSQL 中 ROUND 過載的效能宣告
已新增此部分以瞭解 ROUND 可用的最佳選項。
我們將為此新增一個摘要,以便他們可以瀏覽並進行操作。但是,需要高效和更快解決方案的開發人員可以繼續閱讀詳細說明。
Function Overload比ROUND的 CAST 編碼更快。- 當結合
JIT優化時,SQL 可能會在效能上超過 PLPGSQL。
有兩種方法可以對浮點數或雙精度進行舍入。一個是標準 CAST,另一個是 FUNCTION OVERLOAD。
從 Brubaker Shane 發給 PostgreSQL 的一封電子郵件 here 指出,使用 CAST 運算子會在效能上產生相當大的差異,如果你關閉 SEQ SCANS,成本會高出 7 倍。將此與 FUNCTION OVERLOAD 進行比較,你會發現後者更好。
具有諸如 STABLE 或 IMMUTABLE 等屬性的 FUNCTION OVERLOAD 往往會減少執行函式帶來的開銷,從而顯著提高效能並隨著時間的推移減少問題。
如果每次都呼叫常量引數,則查詢不必重複執行。相反,函式值按原樣返回相同的值。
在我們這裡的函式中,我們使用了語言 SQL 而不是 PLPGSQL,PLPGSQL 也可以使用。如果我們要提高效能,為什麼我們使用 SQL 而不是 PLPGSQL?
PostgreSQL 文件指出 PLPGSQL 是一種更好的程式計算方式。為什麼?
SQL 會以增量方式傳送查詢,處理它們,等待,然後在傳送另一個查詢之前進行計算,PLPGSQL 會將這些計算分組並減少 SQL 傾向於執行的多次解析。
在這種情況下,PLPGSQL 似乎是減少開銷的完美選擇。然而,SQL 往往更適合 JIT OPTIMIZATION。
JIT 代表 JUST-IN-TIME,這意味著它在執行時評估 CPU 最早可以執行的查詢以節省時間。JIT 加速操作使用內聯來減少函式呼叫的開銷。
JIT 會將這些函式的主體內聯到可以執行的不同表示式中。當然,這會降低效能開銷。
JIT OPTIMIZATION 在我們的 PostgreSQL 資料庫中使用 LLVM 基礎架構。在 LLVM 文件的 TRANSFORM PROCESS 部分,你可以看到優化如何工作並有效地產生結果。
PostgreSQL 中具有不同數字表示的 ROUND
浮點數是二進位制表示。如果你還記得,你會意識到浮點數帶有尾數,一個數字表示式,前面有指數增加/減少或前面的符號。
浮點數以三種不同的模式四捨五入:
ROUND TOWARDS ZERO: 1.5 to 1 (truncate extra digits)
ROUND HALF-WAY FROM ZERO: 1.5 to 2 (if fraction equal to half of the base, go forward to the nearest integer)
ROUND HALF TO EVEN (Banker's ROUND): 1.5 to 2 but 2.5 to 2 (we always round off to even, resulting in case of half base to reduce errors)
讓我們從對十進位制浮點數進行四捨五入開始。這種四捨五入很簡單,並遵循四捨五入到底數一半處最接近整數的基本語法。
在開始之前,你必須清楚地瞭解用於四捨五入不同數字表示的公式; DECIMAL、BINARY 和 HEXA-DECIMAL。我們將使用具有不同 RADIX(數字基數)值的標準化 IBM 提供的公式。
公式:
sign(x)* ( b(e-n) ) * floor( abs(x) * ( b(n-e) ) + 1/2
在這個公式中,b 代表基數。e 代表我們想要四捨五入的值的指數。
ABS 代表絕對值,一個正數表示。FLOOR 代表前面最接近的整數。
2.5 的 FLOOR 將是 2,而 CEILING 將是 3。
因此,使用不同的 RADIX 值將為每種表示形式提供不同的答案。如果我們用十進位制表示法對 3.567 進行四捨五入,我們將得到:
3.6 for decimal digit = 1
使用 BINARY,我們會得到:
3.6 for decimal digit = 3/4
並使用十六進位制,
3.6 for decimal digit = 1/2
因此,我們現在可以為這些不同的數字表示建立一個函式。
對於我們的十進位制情況,我們將呼叫 ROUND 函式。但是,我們將更改二進位制和十六進位制的語句。
對於兩者,我們首先將我們的數字分成兩個不同的部分,一個在小數部分之前,另一個在小數部分之後。
如果要四捨五入的數字小於最高有效位,我們會將我們的值截斷為 BIN_BITS 和我們四捨五入的數字之間的差值。否則,我們將截斷這些數字。
CREATE FUNCTION trunc_bin(x bigint, t int) RETURNS bigint AS $f$
SELECT ((x::bit(64) >> t) << t)::bigint;
$f$ language SQL IMMUTABLE;
CREATE FUNCTION ROUND(
x float,
xtype text, -- 'bin', 'dec' or 'hex'
xdigits int DEFAULT 0
)
RETURNS FLOAT AS $f$
SELECT CASE
WHEN xtype NOT IN ('dec','bin','hex') THEN 'NaN'::float
WHEN xdigits=0 THEN ROUND(x)
WHEN xtype='dec' THEN ROUND(x::numeric,xdigits)
ELSE (s1 ||'.'|| s2)::float
END
FROM (
SELECT s1,
lpad(
trunc_bin( s2::bigint, CASE WHEN xd<bin_bits THEN bin_bits - xd ELSE 0 END )::text,
l2,
'0'
) AS s2
FROM (
SELECT *,
(floor( log(2,s2::numeric) ) +1)::int AS bin_bits, -- most significant bit position
CASE WHEN xtype='hex' THEN xdigits*4 ELSE xdigits END AS xd
FROM (
SELECT s[1] AS s1, s[2] AS s2, length(s[2]) AS l2
FROM (SELECT regexp_split_to_array(x::text,'\.')) t1a(s)
) t1b
) t1c
) t2
$f$ language SQL IMMUTABLE;
因此,我們可以使用它在任何可能的數字表示上呼叫 ROUND。
在 PostgreSQL 中使用 TRUNC 進行舍入顯示
你可以使用的另一個函式是 TRUNC 方法,它會在特定標記處截斷值。
所以在位置 2 的 42.346 上呼叫 TRUNC 將使它:
42.34
如果需要四捨五入到最接近的 FLOOR 整數,可以使用 TRUNC,如下所示:
SELECT TRUNC(42.346, 2)

Hello, I am Bilal, a research enthusiast who tends to break and make code from scratch. I dwell deep into the latest issues faced by the developer community and provide answers and different solutions. Apart from that, I am just another normal developer with a laptop, a mug of coffee, some biscuits and a thick spectacle!
GitHub