刪除 MySQL 中的重複行
本文將向你展示在 MySQL 中刪除表中存在的重複行的多種方法。有四種不同的方法來完成這項任務。
- 使用
DELETE JOIN語句刪除重複行 - 使用巢狀查詢刪除重複行
- 使用臨時表刪除重複行
- 使用
ROW_NUMBER()函式刪除重複行
以下指令碼建立一個包含四列(custid、first_name、last_name 和 email)的表 customers。
CREATE TABLE customers (custid INT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, email VARCHAR(255) NOT NULL );
CREATE TABLE customers (custid INT, first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, email VARCHAR(255) NOT NULL );
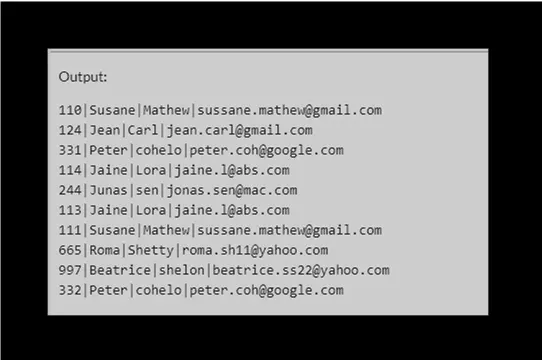
將示例資料值插入 customers 表以進行演示。
INSERT INTO customers
VALUES (110,'Susane','Mathew','sussane.mathew@gmail.com'),
(124,'Jean','Carl','jean.carl@gmail.com'),
(331,'Peter','cohelo','peter.coh@google.com'),
(114,'Jaine','Lora','jaine.l@abs.com'),
(244,'Junas','sen','jonas.sen@mac.com');
INSERT INTO customers
VALUES (113,'Jaine','Lora','jaine.l@abs.com'),
(111,'Susane','Mathew','sussane.mathew@gmail.com'),
(665,'Roma','Shetty','roma.sh11@yahoo.com'),
(997,'Beatrice','shelon','beatrice.ss22@yahoo.com'),
(332,'Peter','cohelo','peter.coh@google.com');
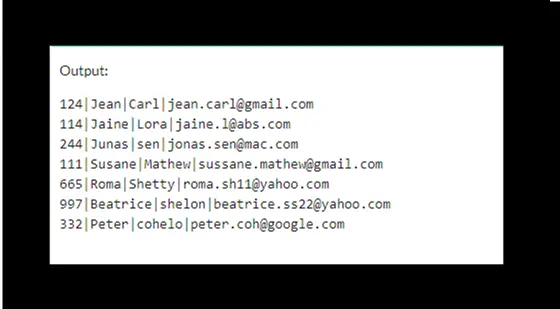
下面是從 customers 表返回所有資料的給定查詢:
SELECT * FROM customers order by custid;
為了從表中查詢重複記錄,我們將在 customers 表中執行下面提到的查詢。
SELECT custid, COUNT(custid) FROM customers GROUP BY custid HAVING COUNT(custid) > 1;
如你所見,我們的結果中有三行具有重複的客戶 ID。
使用 DELETE JOIN 語句刪除重複行
使用 INNER JOIN 和 delete statement 允許你從 MySQL 的表中刪除重複的行。
以下查詢通過選擇具有最低客戶 ID 的重複記錄的所有行來使用巢狀查詢的概念。找到後,我們將刪除這些具有最低 custid 的重複記錄:
Delete from customers where custid IN (Select c1.custid FROM customers as c1
INNER JOIN customers as c2 ON c1.custid < c2.custid AND c1.email = c2.email);
在這個查詢中客戶表被引用了兩次;因此,它使用別名 c1 和 c2。
輸出將是:
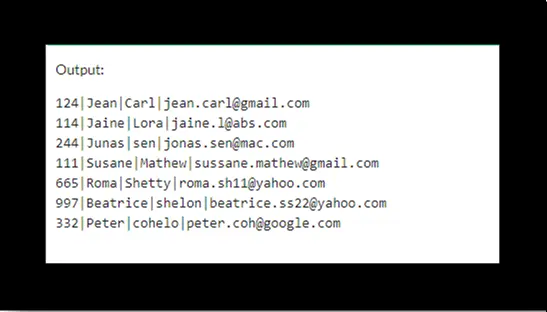
它表示已刪除三行。
SELECT custid, COUNT(custid) FROM customers GROUP BY custid HAVING COUNT(custid) > 1;
現在,此查詢返回一個空集,這意味著重複的行已被刪除。
我們可以使用 select 查詢來驗證 customers 表中的資料:
SELECT * FROM customers;
如果你希望刪除重複的行並保留最低的 custid,那麼你可以使用相同的查詢,但條件略有不同,如以下語句所示:
Delete from customers where custid IN (Select c1.custid FROM customers as c1
INNER JOIN customers as c2 ON c1.custid > c2.custid AND c1.email = c2.email);
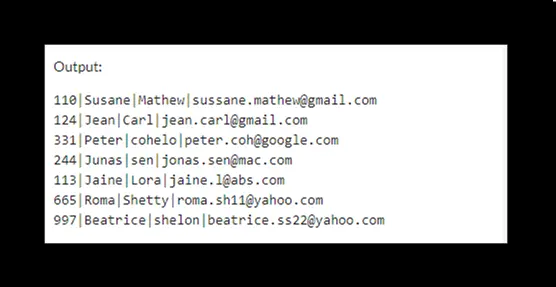
以下輸出顯示了刪除重複行後 customers 表的資料。
使用巢狀查詢刪除重複行
現在讓我們看一下使用巢狀查詢刪除重複行的分步過程。這是解決問題的一種比較直接的方法。
首先,我們將使用此查詢從表中選擇唯一記錄。
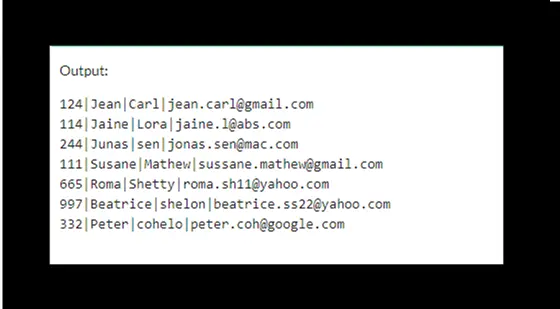
Select * from (select max(custid) from customers group by email);
然後我們將使用帶有 where 子句的 delete 查詢,如下所示,刪除表中的重複行。
Delete from customers where custid not in
(select * from (select max(custid) from customers group by email));
輸出將是:
使用臨時表刪除重複行
現在讓我們看一下使用臨時表刪除重複行的分步過程:
- 首先,你需要建立一個與原表結構相同的新表。
- 現在,將原始表中的不同行插入到臨時表中。
- 刪除原表,將臨時表重新命名為原表。
第 1 步:使用 CREATE TABLE 和 LIKE 關鍵字建立表
複製整個表結構的語法如下所示。
CREATE TABLE destination_table LIKE source;
因此,假設我們有相同的客戶表,我們將編寫下面給出的查詢。
CREATE TABLE temporary LIKE customers;
步驟 2. 在臨時表中插入行
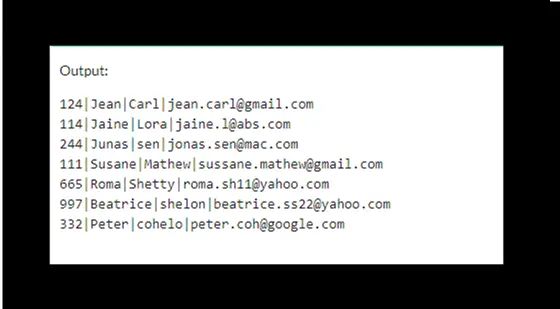
下面給出的查詢從客戶複製唯一行並將其寫入臨時表。在這裡,我們按電子郵件分組。
INSERT INTO temporary SELECT * FROM customers GROUP BY email;
步驟 3. 刪除原始客戶表並通過將其重新命名為客戶來建立一個臨時表作為原始表。
DROP TABLE customers;
ALTER TABLE temporary RENAME TO customers;
輸出將是:
這種方法很耗時,因為它需要更改表的結構,而不僅僅是處理資料值。
使用 ROW_NUMBER() 函式刪除重複行
ROW_NUMBER() 函式已在 MySQL 8.02 版中引入。因此,如果你執行的是高於 8.02 的 MySQL 版本,則可以採用這種方法。
此查詢使用 ROW_NUMBER() 函式為每一行分配一個數值。在重複電子郵件的情況下,行號將大於一。
SELECT custid, email, ROW_NUMBER() OVER ( PARTITION BY email ORDER BY email ) AS row FROM customers;
上面的程式碼片段返回重複行的 id 列表:
SELECT custid
FROM ( SELECT custid, ROW_NUMBER() OVER (PARTITION BY email ORDER BY email) AS row FROM customers) t WHERE row > 1;
一旦我們獲得具有重複值的客戶列表,我們可以使用 delete 語句在 where 子句中使用子查詢刪除它,如下所示。
DELETE FROM customers
WHERE custid IN
(SELECT custid FROM
(SELECT custid, ROW_NUMBER() OVER
(PARTITION BY email ORDER BY email) AS row FROM customers) t
WHERE row > 1);
輸出將是: