在 MongoDB 的查詢操作中使用管道

本教程教授如何在 MongoDB 的 lookup 運算子中使用管道。在繼續之前,必須對聚合管道和 $lookup 運算子有足夠的瞭解,以便在使用 MongoDB 時瞭解 $lookup 運算子中管道的使用。
如果你已經瞭解這些概念,則可以快速轉到本教程的最後兩個程式碼示例。
什麼是聚合管道
它是收集資料並返回計算結果的過程。這個過程從不同的文件中收集資料,按照指定的條件對它們進行分組,並對分組後的資料進行各種操作。
例如,平均值、總和、最大值和最小值。它就像 SQL 聚合函式一樣。
在 MongoDB 中,我們可以通過以下三種方式使用聚合。
-
聚合管道 - 包含轉換所提供文件的各個階段。每個階段都接受一組文件並生成另一組結果文件,這些文件進一步傳遞到下一個階段,這個過程一直持續到最後階段。
-
Map-reduce 功能 - 我們使用此功能來大規模聚合結果。它有兩個功能,
map和reduce。map方法對所有文件進行分組,而reduce方法對分組資料執行操作。 -
單一用途的聚合——用於執行聚合任務的最簡單的聚合形式,但與聚合管道方法相比缺乏一些特性。我們使用這種型別的聚合來執行特定文件中的任務,例如,計算特定文件中的不同值。
你還可以閱讀 this 以更深入地瞭解聚合管道。
什麼是 MongoDB 中的 $lookup 運算子
此運算子用於執行左外連線以將資料從一個文件合併到同一資料庫中的另一個文件。它從連線的集合中過濾文件以進行進一步處理。
我們還可以使用此運算子向現有文件新增額外欄位。
$lookup 運算子新增了一個新的陣列屬性(欄位),其值(元素)與連線集合中的文件匹配。然後將這些轉換後的文件傳遞到下一階段。
$lookup 運算子具有三種不同的語法,我們可以根據專案要求使用。本教程使用 $lookup 語法來表示 Join conditions & Subqueries on the Joined Collection。
為了練習示例程式碼,讓我們用資料準備示例集合。
示例程式碼:
db.createCollection('collection1');
db.createCollection('collection2');
db.collection1.insertMany([
{"shopId": "001", "shopPosId": "001", "description": "description for 001"},
{"shopId": "002", "description": "description for 002"},
{"shopId": "003", "shopPosId": "003", "description": "description for 003"},
{"shopId": "004", "description": "description for 004"}
]);
db.collection2.insertMany([
{"shopId": "001", "shopPosId": "0078", "clientUid": "474192"},
{"shopId": "002", "shopPosId": "0012", "clientUid": "474193"},
{"shopId": "003", "shopPosId": "0034", "clientUid": "474194"},
{"shopId": "004", "shopPosId": "0056", "clientUid": "474195"}
]);
現在,我們可以執行以下命令來檢視每個集合中插入的文件。
db.collection1.find();
db.collection2.find();
在 $lookup 運算子中使用管道連線 MongoDB 中的條件
要了解如何在 $lookup 運算子中使用管道,讓我們連線兩個集合中的文件,其中 collection1.shopId 等於 collection2.shopId,而 collection1 不包含 shopPosId 欄位.
只有滿足這兩個條件的兩個集合才會連線那些文件。請參閱下面給出的示例程式碼。
示例程式碼:
db.collection2.aggregate([
{
"$lookup": {
"from": "collection1",
"let": { "shopId": "$shopId" },
"pipeline": [{
"$match": {
"$and": [
{"$expr": {"$eq": ['$shopId', '$$shopId'] }},
{ "shopPosId": { "$exists": false } }
]
}
}],
"as": "shopDescription"
}
}
]).pretty();
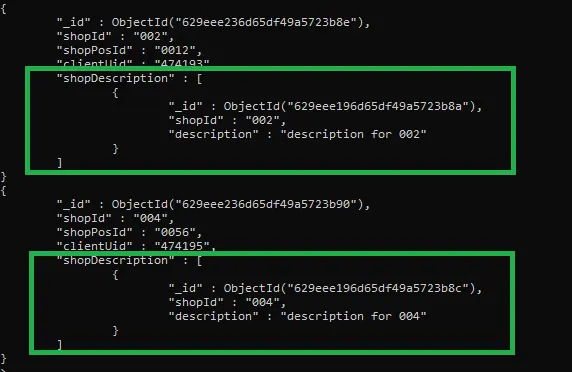
輸出:
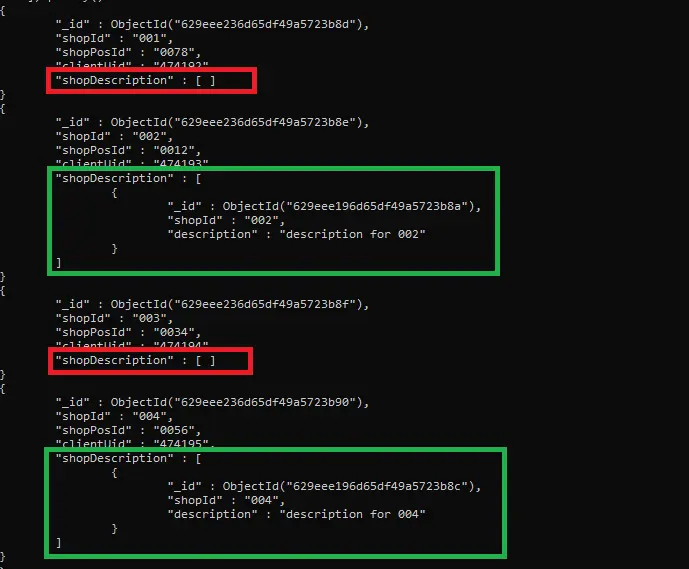
你是否仔細觀察了上面給出的輸出?只有那些文件從滿足管道中兩個條件的兩個集合中加入(collection1.shopId 等於 collection2.shopId,並且 collection1 不包含 shopPosId 欄位)。
此外,那些不符合這些條件的文件有一個名為 shopDescription 的空陣列(參見上面結果中的紅色框)。我們只能顯示那些包含非空 shopDescription 陣列的結果文件(請參閱以下查詢)。
示例程式碼:
db.collection2.aggregate([
{
"$lookup": {
"from": "collection1",
"let": { "shopId": "$shopId" },
"pipeline": [{
"$match": {
"$and": [
{"$expr": {"$eq": ['$shopId', '$$shopId'] }},
{ "shopPosId": { "$exists": false } }
]
}
}],
"as": "shopDescription"
}
},
{
"$match":{
"shopDescription": { $exists: true, $not: {$size: 0} }
}
}
]).pretty();
輸出: