Python pandas.pivot_table() 函式
Minahil Noor
2023年1月30日
-
pandas.pivot_table()的語法 -
示例程式碼:
pandas.pivot_table() -
示例程式碼:
pandas.pivot_table()指定多個聚合函式 -
示例程式碼:
pandas.pivot_table()使用margins引數
Python Pandaspandas.pivot_table() 函式避免了 DataFrame 的資料重複。它對資料進行彙總,並對資料應用不同的聚合函式。
pandas.pivot_table() 的語法
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)
引數
這個函式有幾個引數。所有引數的預設值如上所述。
data |
這是 DataFrame,我們要從中刪除重複的資料。 |
values |
它代表要彙總的列 |
index |
它是一個列、grouper、陣列或列表。它代表我們想要作為索引的資料列,即行。 |
columns |
它是一個列、grouper、陣列或列表。它代表了我們希望在輸出資料透視表中作為列的資料列。 |
aggfunc |
它是一個函式、函式列表或字典。它代表將應用於資料的聚合函式。如果傳遞的是聚合函式的列表,那麼在結果表中,每個聚合函式將有一列,列名在頂部。 |
fill_value |
它是一個標量。它表示將取代輸出表中缺失值的數值。 |
margins |
這是一個布林值。它代表了在取了各自行和列的和之後生成的行和列。 |
dropna |
它是一個布林值。它從輸出表中刪除值為 NaN 的列。 |
margins_name |
它是一個 “字串”。它表示如果 margins 值為 True 時生成的行和列的名稱。 |
observed |
它是一個布林值。如果任何分組是分類的,那麼這個引數就適用。如果為 True,則顯示分類分組的觀察值。如果是 False,則顯示分類分組的所有值。 |
返回值
它返回彙總後的 DataFrame。
示例程式碼:pandas.pivot_table()
讓我們通過實現這個函式來深入瞭解它。
import pandas as pd
dataframe = pd.DataFrame({
"Name":
["Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan"],
"Date":
["03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019"],
"Science Marks":
[10,
2,
4,
6,
8,
9,
1,
10]
})
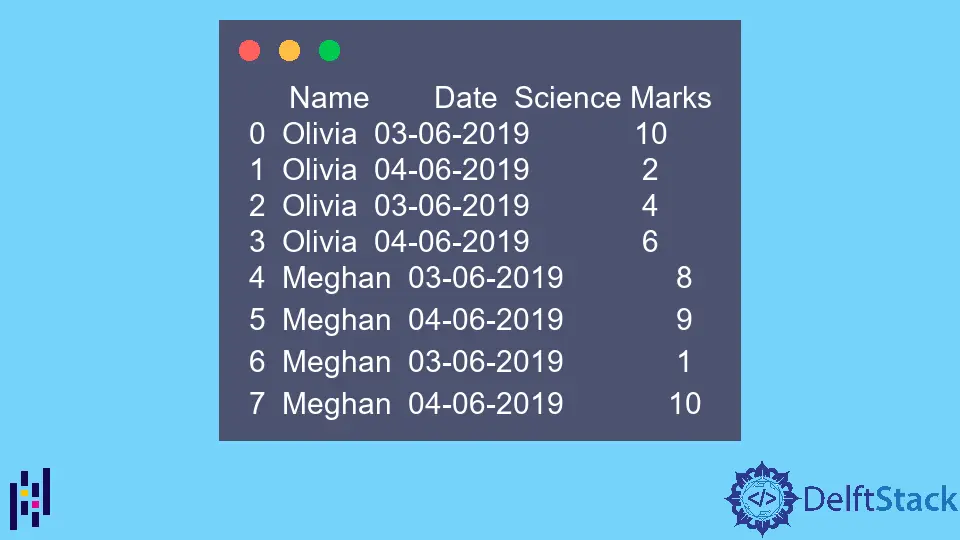
print(dataframe)
示例 DataFrame 的是:
Name Date Science Marks
0 Olivia 03-06-2019 10
1 Olivia 04-06-2019 2
2 Olivia 03-06-2019 4
3 Olivia 04-06-2019 6
4 Meghan 03-06-2019 8
5 Meghan 04-06-2019 9
6 Meghan 03-06-2019 1
7 Meghan 04-06-2019 10
請注意,上述資料在一列中多次包含相同的值。這個 pivot_table 函式將彙總這些資料。
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(dataframe, index="Name", columns="Date")
print(pivotTable)
輸出:
Science Marks
Date 03-06-2019 04-06-2019
Name
Meghan 4.5 9.5
Olivia 7.0 4.0
這裡,我們選擇了 Name 列作為索引,Date 作為列。函式已經根據預設引數生成了結果。預設的聚合函式 mean 計算了數值的平均值。
示例程式碼:pandas.pivot_table() 指定多個聚合函式
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"]
)
print(pivotTable)
輸出:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 03-06-2019 04-06-2019
Name
Meghan 9 19 2 2
Olivia 14 8 2 2
我們使用了兩個彙總函式。這些函式的列是單獨生成的。
示例程式碼:pandas.pivot_table() 使用 margins 引數
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"], margins=True
)
print(pivotTable)
輸出:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 All 03-06-2019 04-06-2019 All
Name
Meghan 9 19 28 2 2 4
Olivia 14 8 22 2 2 4
All 23 27 50 4 4 8
margins 引數生成了一個名為 All 的新行和一個名為 All 的新列,分別顯示行和列的和。